Chain(
layer_1 = Dense(1 => 2, relu), # 4 parameters
layer_2 = Dense(2 => 1), # 3 parameters
) # Total: 7 parameters,
# plus 0 states.
Machine Learning for Computational Economics
Module 04: Fundamentals of Machine Learning
EDHEC Business School
January 2026
ImageNet Image and its RGB Channels




Linear Regression
To illustrate the key concepts in supervised learning, it is useful to start with a familiar model: linear regression.
- Suppose we are given a dataset of \(I\) observations of the input \(\mathbf{x}_i \in \mathbb{R}^d\) and output \(y_i \in \mathbb{R}\) for \(i = 1, \ldots, I\).
- Given the input \(\mathbf{x}_i\), the model prediction \(\hat{y}_i\) is given by the function \(f(\mathbf{x}_i, \mathbf{\theta})\), where \(\mathbf{\theta} \in \mathbb{R}^d\) is a vector of parameters. \[ f(\mathbf{x}_i, \mathbf{\theta}) = \color{#0072b2}{\underbrace{\mathbf{w}^{\top}}_{\text{weights}}}\mathbf{x}_i + \color{#d55e00}{\underbrace{b}_{\text{bias}}} \] where \(\mathbf{\theta} = (\mathbf{w}^{\top}, b)^{\top}\).
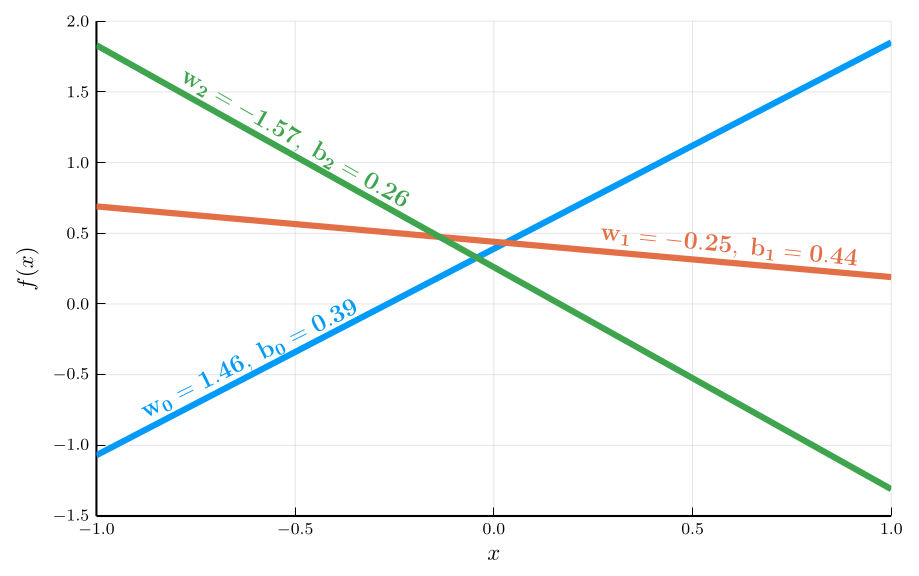
The function \(f(\mathbf{x}_i, \mathbf{\theta})\) defines a family of linear functions
- We obtain different functions by varying the parameters \(\mathbf{\theta}\).
Our goal is to find the parameter values that best fit the data.
- To do this, we define a loss function that measures model fit: \[ \mathcal{L}(\mathbf{\theta}) = \frac{1}{2I} \sum_{i=1}^I (y_i - f(\mathbf{x}_i, \mathbf{\theta}))^2. \] This is the mean squared error (MSE) loss function.
Loss Surface
The loss surface shows the loss for different parameter values.
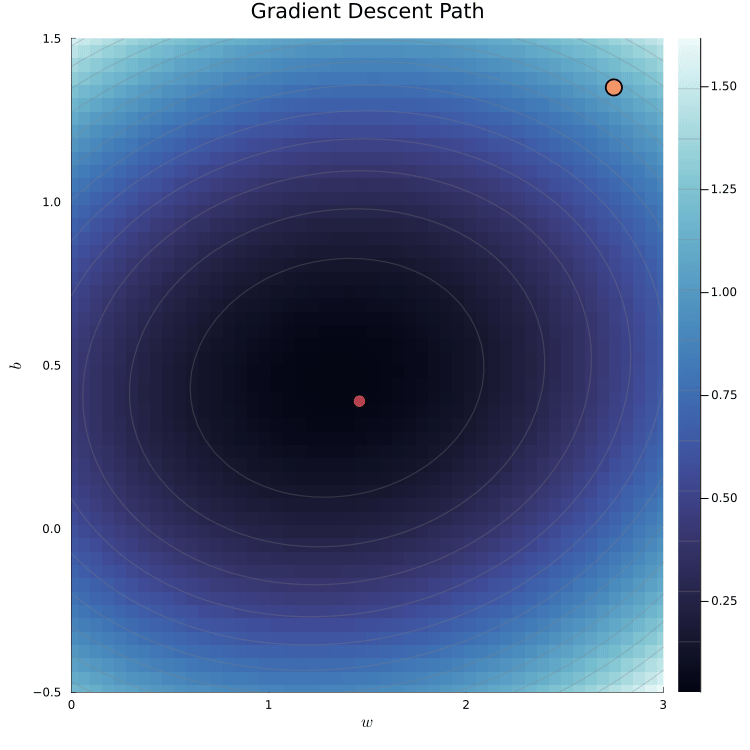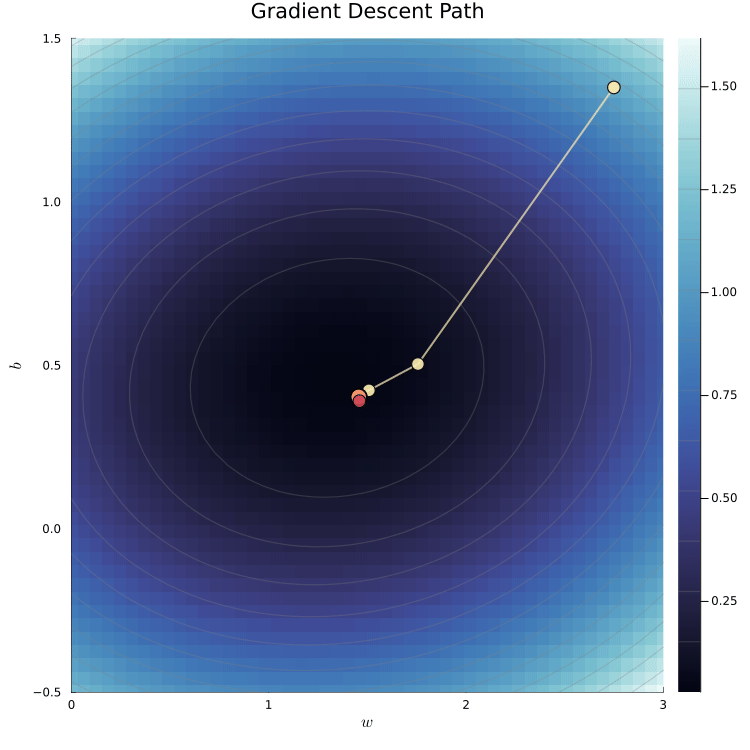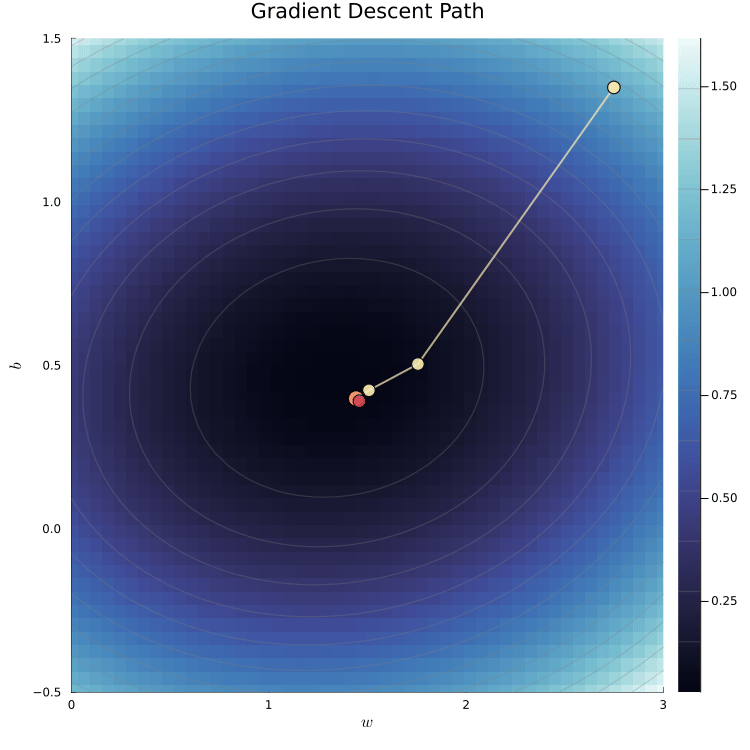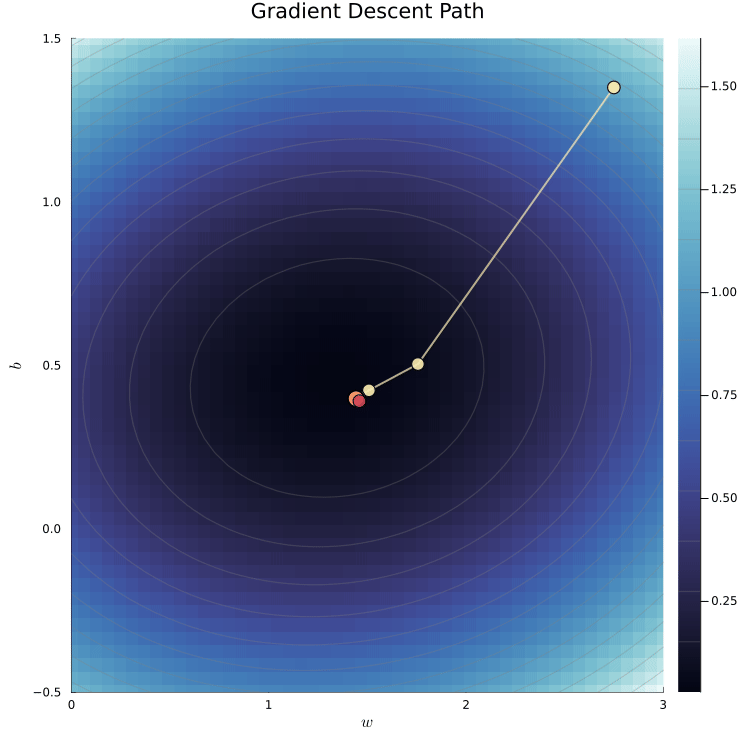
We can visualize the loss surface as a heatmap.
- The minimum of the loss surface is the parameter values that best fit the data.
- This corresponds to the darkest region in the heatmap.
The animation shows the gradient descent path being traced
The yellow path shows how the algorithm moves toward the minimum.
The red dot marks the true parameter values used to simulate the data.
The algorithm converges to the minimum of the loss surface.
Training and Testing
In the discussion above, we used all available data to estimate the parameters.
- In practice, we typically split the data into a training set and a test set.
- The training set is used to estimate the parameters, the test set is used to evaluate how well the model fits new data.
Consider data generated by a noisy version of the Runge function: \[ y_i = \frac{1}{1+25 z_i^2} + \epsilon_i, \qquad \epsilon_i \sim \text{i.i.d. with } \mathbb{E}[\epsilon_i]=0, \] with \(z_i \in [-1,1]\).
Consider a polynomial regression with regressors: \[ \mathbf{x}_i = [z_i, z_i^2, \ldots, z_i^{d-1}] \]
As the degree \(d\) increases, the model becomes more flexible.
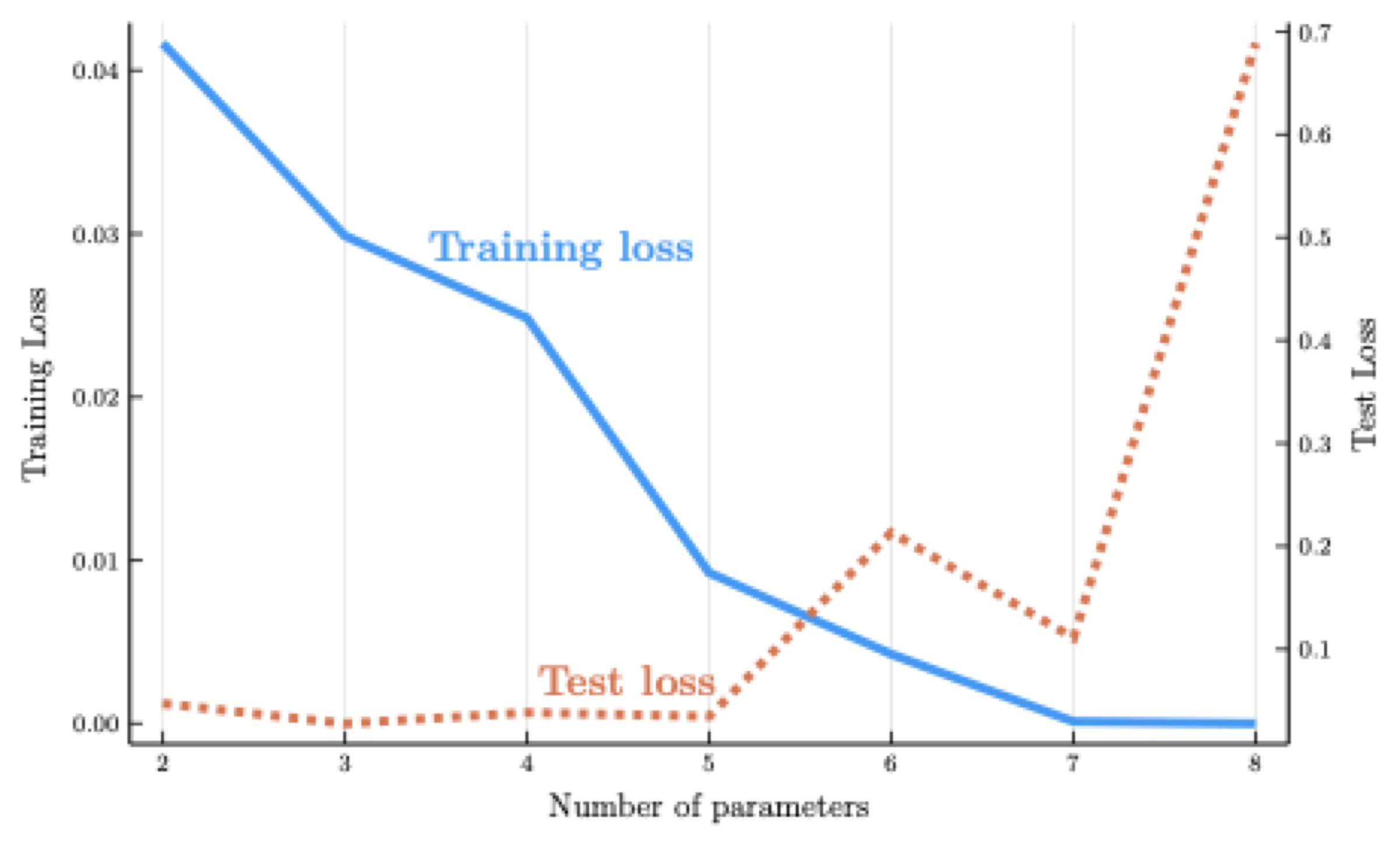
When \(d = I\), the model reaches the interpolation threshold.
But high-degree polynomial interpolants of the Runge function oscillate violently.
The model performs poorly on the test set for high \(d\).
The figure shows the training loss declines steadily as \(d\) increases
- But the test loss eventually rises: this is the hallmark of overfitting
Shallow Neural Networks
We now move from linear to nonlinear models by introducing the shallow neural network (SNN).
- An SNN can be viewed as a generalization of the linear regression model
- A series of intermediate transformations combines a linear function with a nonlinear activation.
Hidden units: a nonlinear transformations of the inputs. \[ h_j(\mathbf{x}, \mathbf{\theta}_j) = \sigma(\mathbf{w}_j^{\top} \mathbf{x} + b_j), \qquad j = 0, \ldots, n-1 \] where \(\sigma\) is an activation function, \(\mathbf{\theta}_j = (\mathbf{w}_j^{\top}, b_j)^{\top}\).
The SNN can be written as: \[ f(\mathbf{x}, \mathbf{\theta}) = \mathbf{w}_n^{\top} \mathbf{h}(\mathbf{x}, \mathbf{\theta}) + b_n, \] where \(\mathbf{\theta} = (\mathbf{\theta}_0^{\top}, \ldots, \mathbf{\theta}_{n}^{\top})^{\top}\) and \(\mathbf{\theta}_n = (\mathbf{w}_n^{\top}, b_n)^{\top}\).
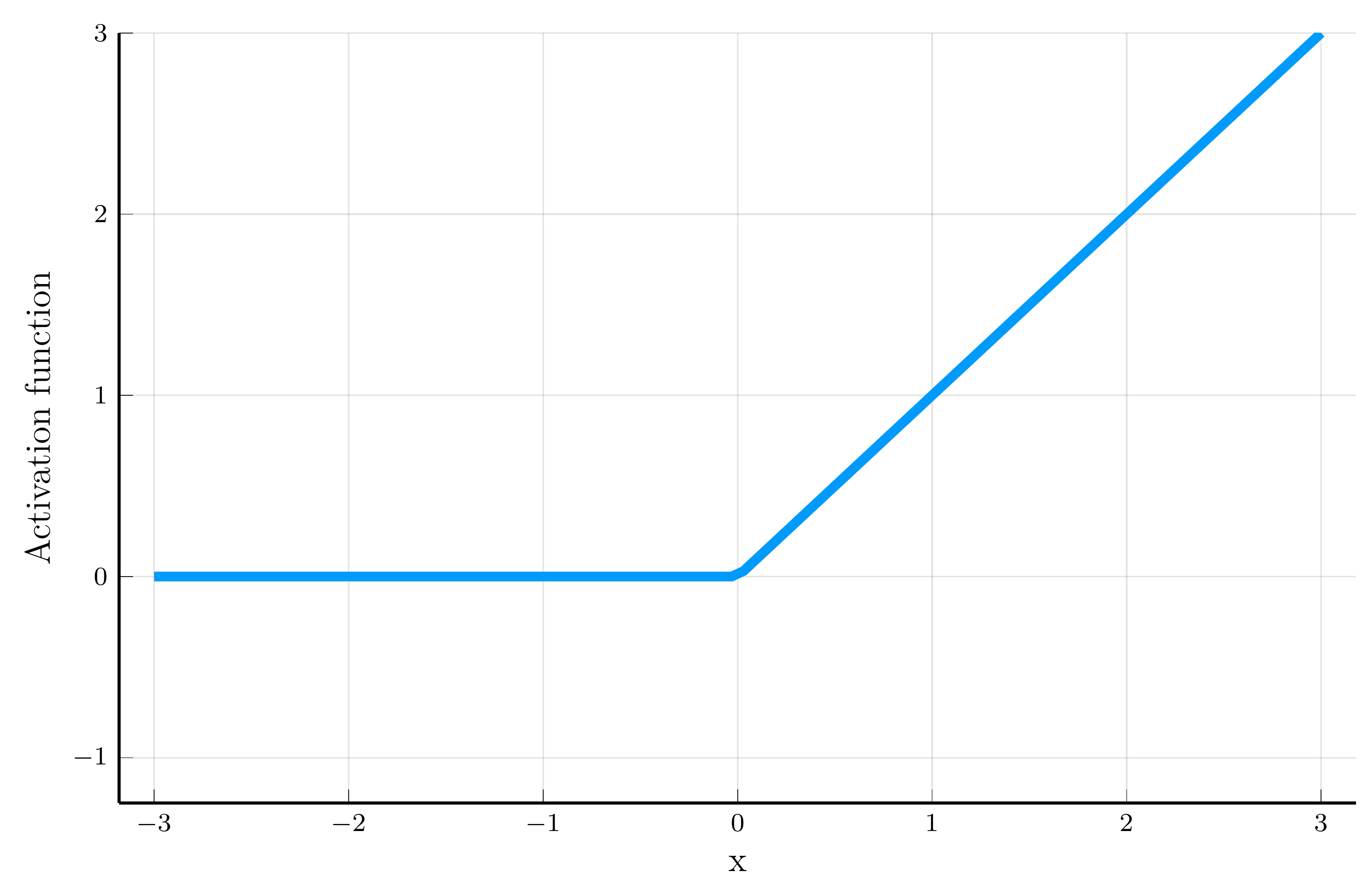
The rectified linear unit (ReLU): \[ \sigma(x) = \max(0, x). \]
This is the mostly used activation function in machine learning.
- We will often focus on the ReLU.

The Gaussian Error Linear Unit (GELU): \[ \sigma(x) = x \Phi(x), \] where \(\Phi(x)\) is the standard normal cdf.
- It has been shown to improve performance in many applications.
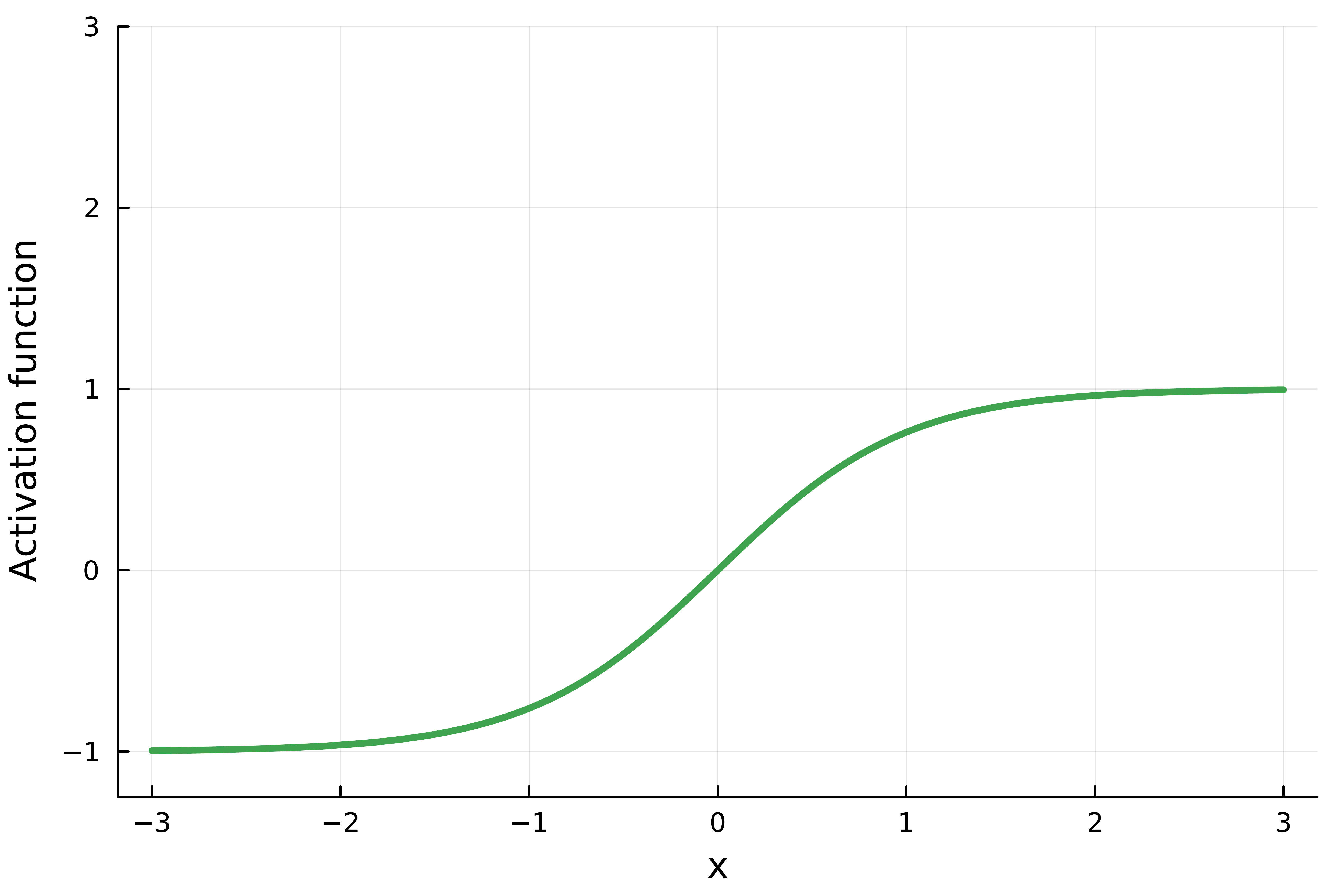
The hyperbolic tangent (tanh): \[ \sigma(x) = \frac{1 - e^{-2x}}{1 + e^{-2x}}. \] It is historically popular in recurrent networks.
- It provides smooth, bounded outputs between -1 and 1.

The Sigmoid Linear Unit (SiLU): \[ \sigma(x) = \frac{x}{1 + e^{-x}}. \] Also known as Swish.
- SiLU yields smooth gradients even for negative inputs.
SNNs Architecture and Implementation
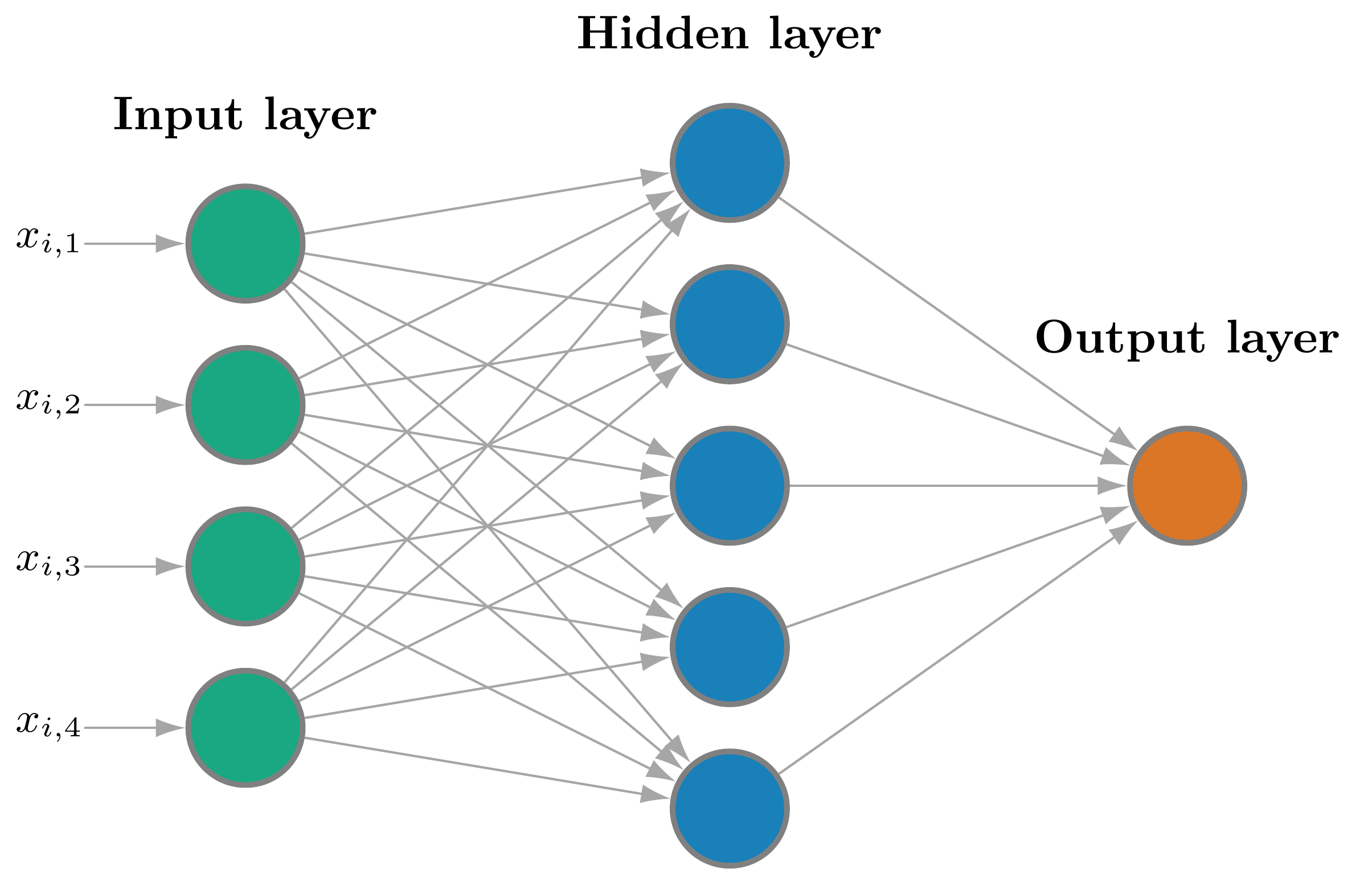
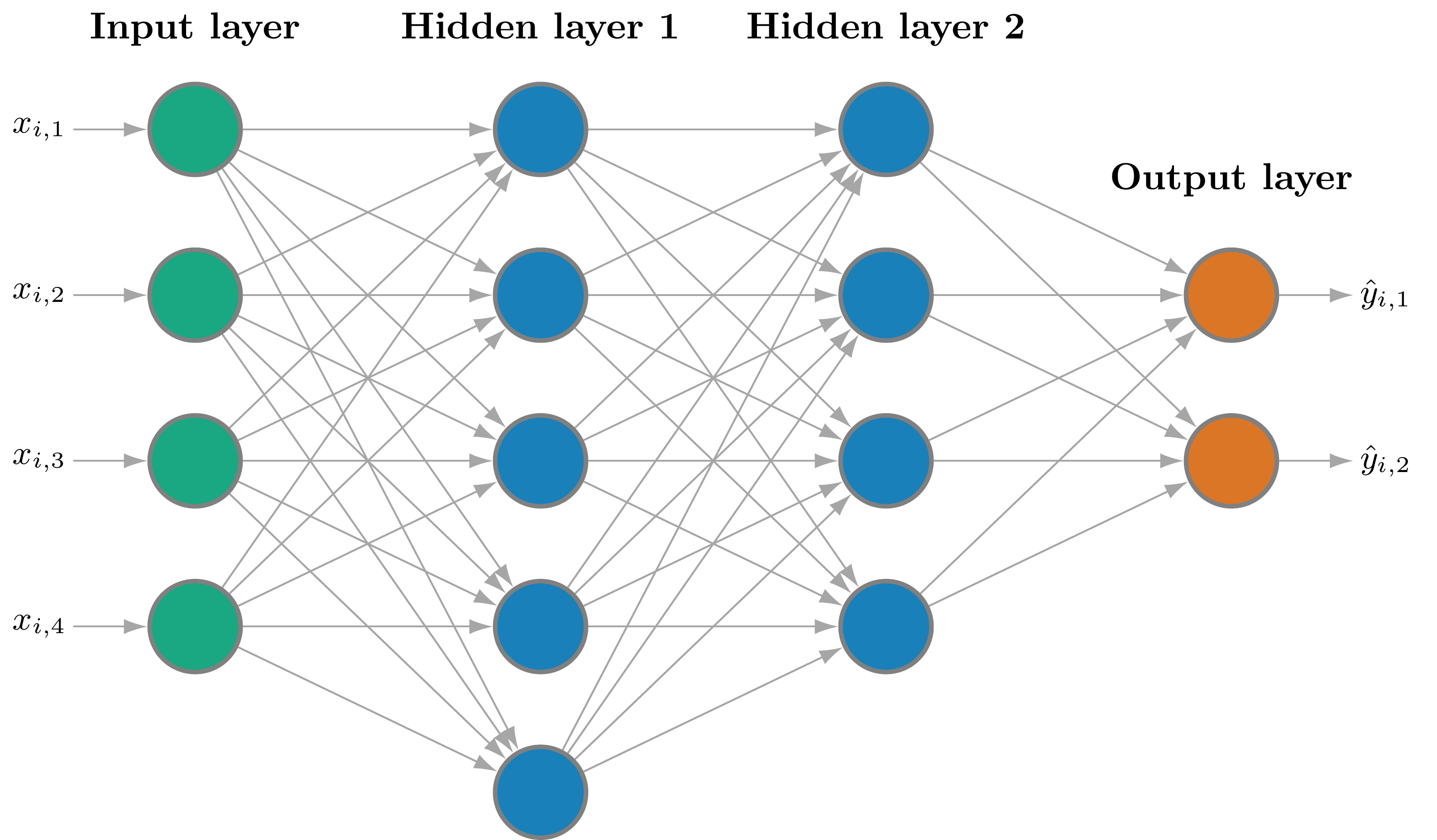
This figure illustrates the architecture of an SNN.
- Green nodes: input layer.
- Blue nodes: hidden layer.
- Orange node: output layer.
The hidden units are also known as neurons.
- A neural network is a collection of neurons.
- A shallow neural network has a single hidden layer.
function shallow_nn(x::AbstractVector{<:Real},
W::AbstractMatrix{<:Real}, b::AbstractVector{<:Real},
wₙ::AbstractVector{<:Real}, bₙ::Real; σ::Function = x->max(0,x))
@assert size(W,2) == length(x) # ncols of W = length of x
@assert size(W,1) == length(wₙ) # nrows of W = length of wₙ
@assert length(b) == size(W,1) # biases for the hidden units
return wₙ' * σ.(W * x .+ b)+ bₙ
end
# Convenience: scalar input (d = 1); w is the column of W
function shallow_nn(x::Real,
w::AbstractVector{<:Real}, b::AbstractVector{<:Real},
wₙ::AbstractVector{<:Real}, bₙ::Real; σ::Function = x->max(0,x))
return shallow_nn([x], reshape(w,length(w),1), b, wₙ, bₙ, σ = σ)
endSNNs as Piecewise Linear Functions
To illustrate the structure of an SNN, consider a one-dimensional input \(x_i \in [0,1]\) and a ReLU activation function.
- Assume that all hidden-unit weights are \(w_j = 1\).
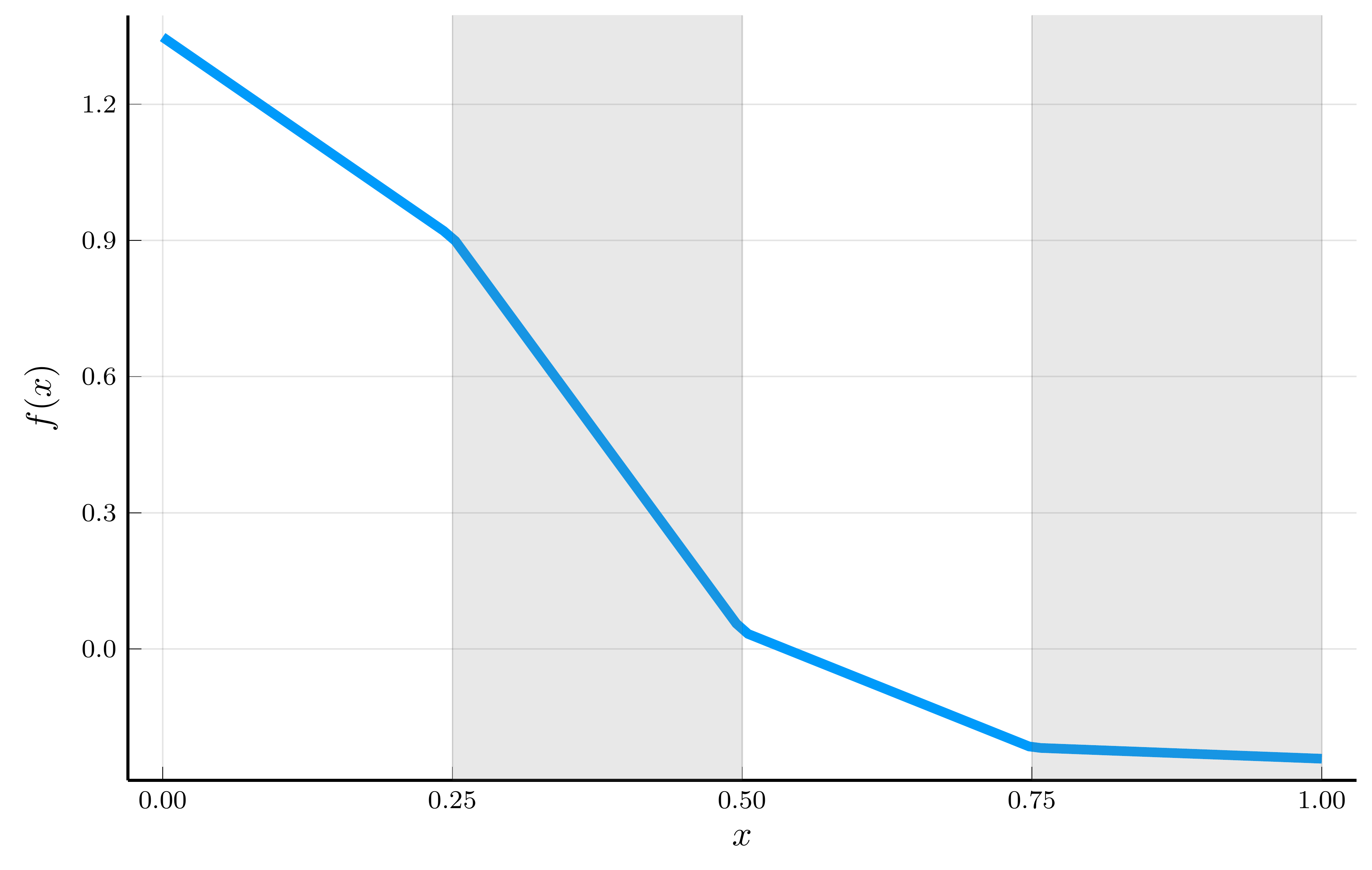
\[ SNN: f(x_i, \theta) = \sum_{j=0}^{n-1} w_{n,j} \max(0, x_i - \hat{x}_j) + b_n, \] where \(\hat{x}_j \equiv - b_j\) is a convenient reparametrization of the biases.
Ordering the breakpoints as \(0 = \hat{x}_0 < \cdots < \hat{x}_{n-1} < 1 \equiv \hat{x}_n\), \[ f(x_i, \theta) = f(\hat{x}_j, \theta) + w_{n,j}(x_i - \hat{x}_j), \qquad x_i \in (\hat{x}_j, \hat{x}_{j+1}], \] with \(f(\hat{x}_0, \theta) = b_n\).
The function is piecewise linear, with the breakpoints \(\hat{x}_j\) learned by the model.
- If we fix the breakpoints to be equally spaced, the network collapses to the locally linear interpolant from Module 3.
- Hence, an SNN can be interpreted as a finite-difference method with an adaptive grid that learns where to place the nodes.
The Adaptive Choice of Breakpoints in Action
ReLU networks adaptively place their breakpoints in regions where the target function exhibits strong nonlinearity.
- To illustrate this, we fit a one–hidden–layer ReLU network to the density of a Beta distribution
- We choose parameters \(\alpha=2\) and \(\beta=10\), so the curvature is concentrated at low \(x\) values.
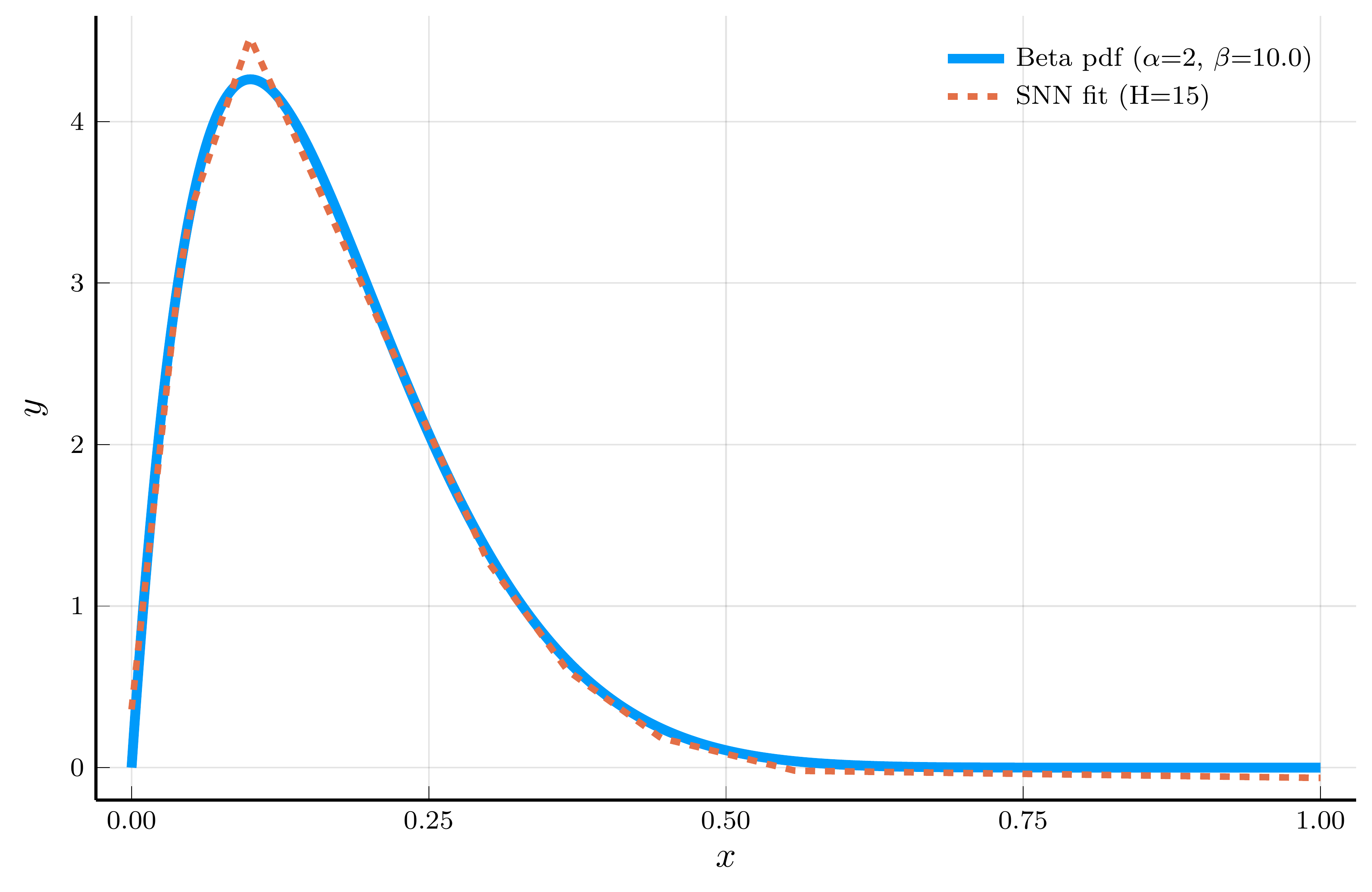
Model fit (15 hidden units)
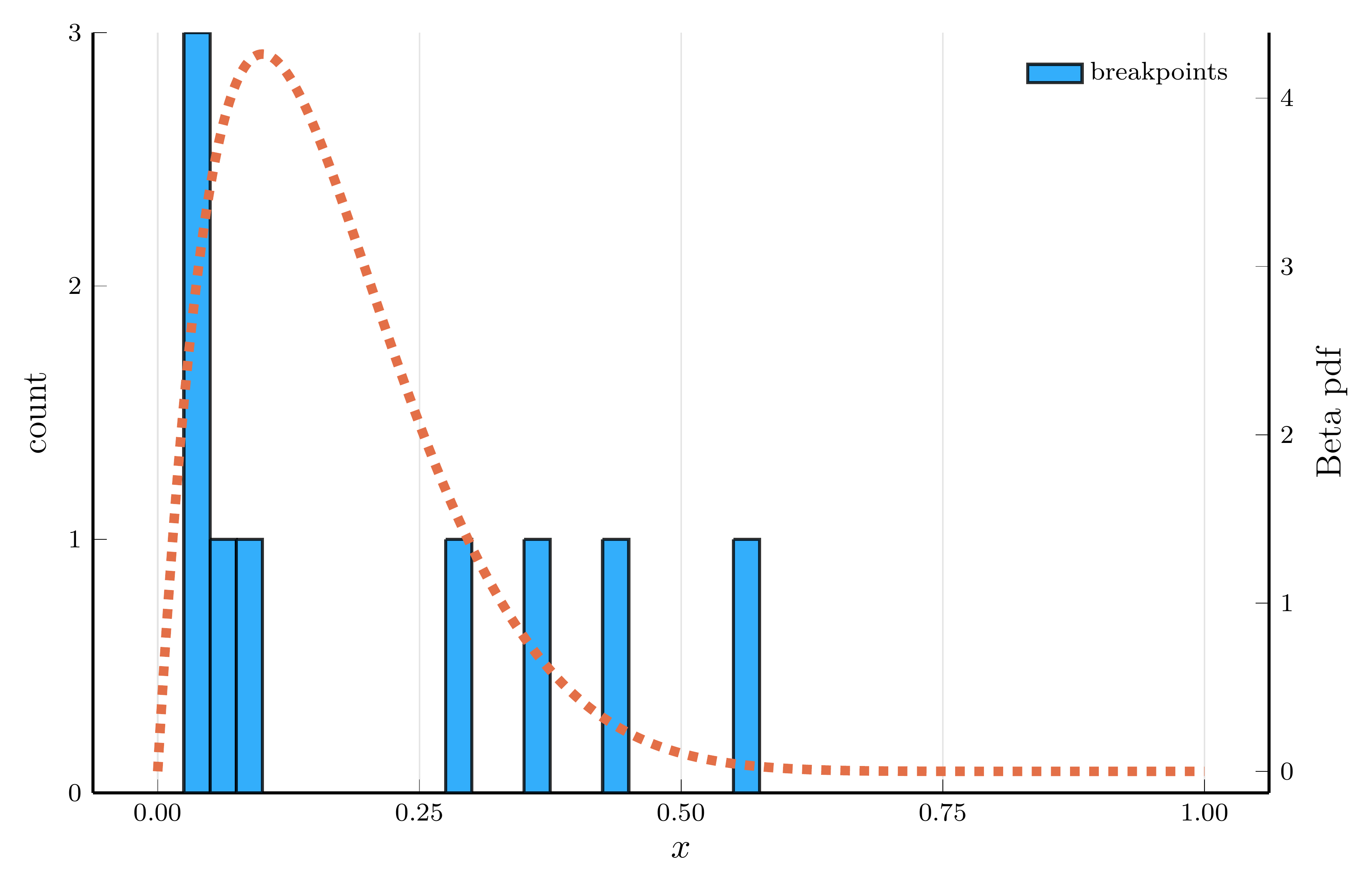
Breakpoint histogram (15 hidden units)
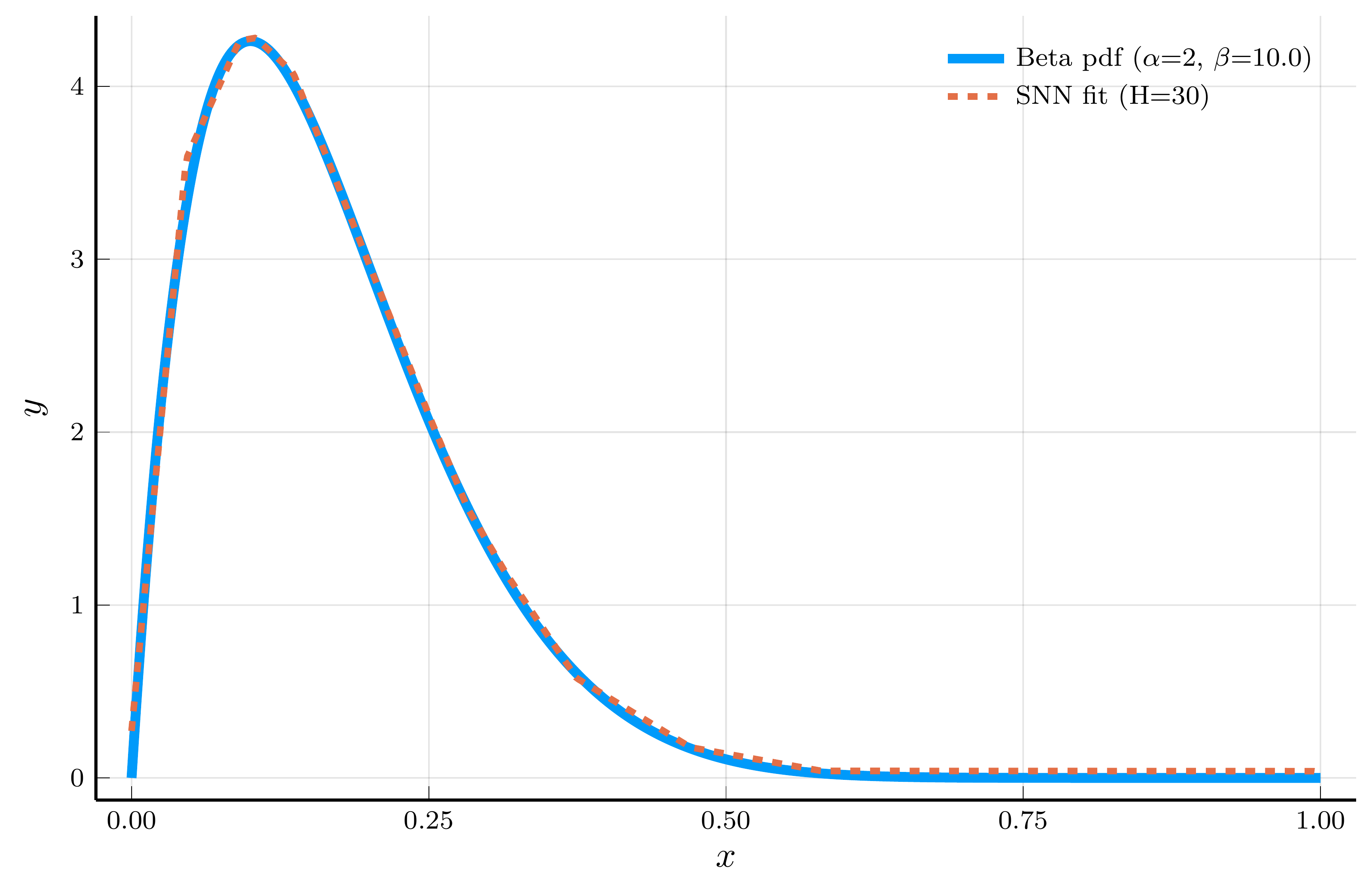
Model fit (30 hidden units)
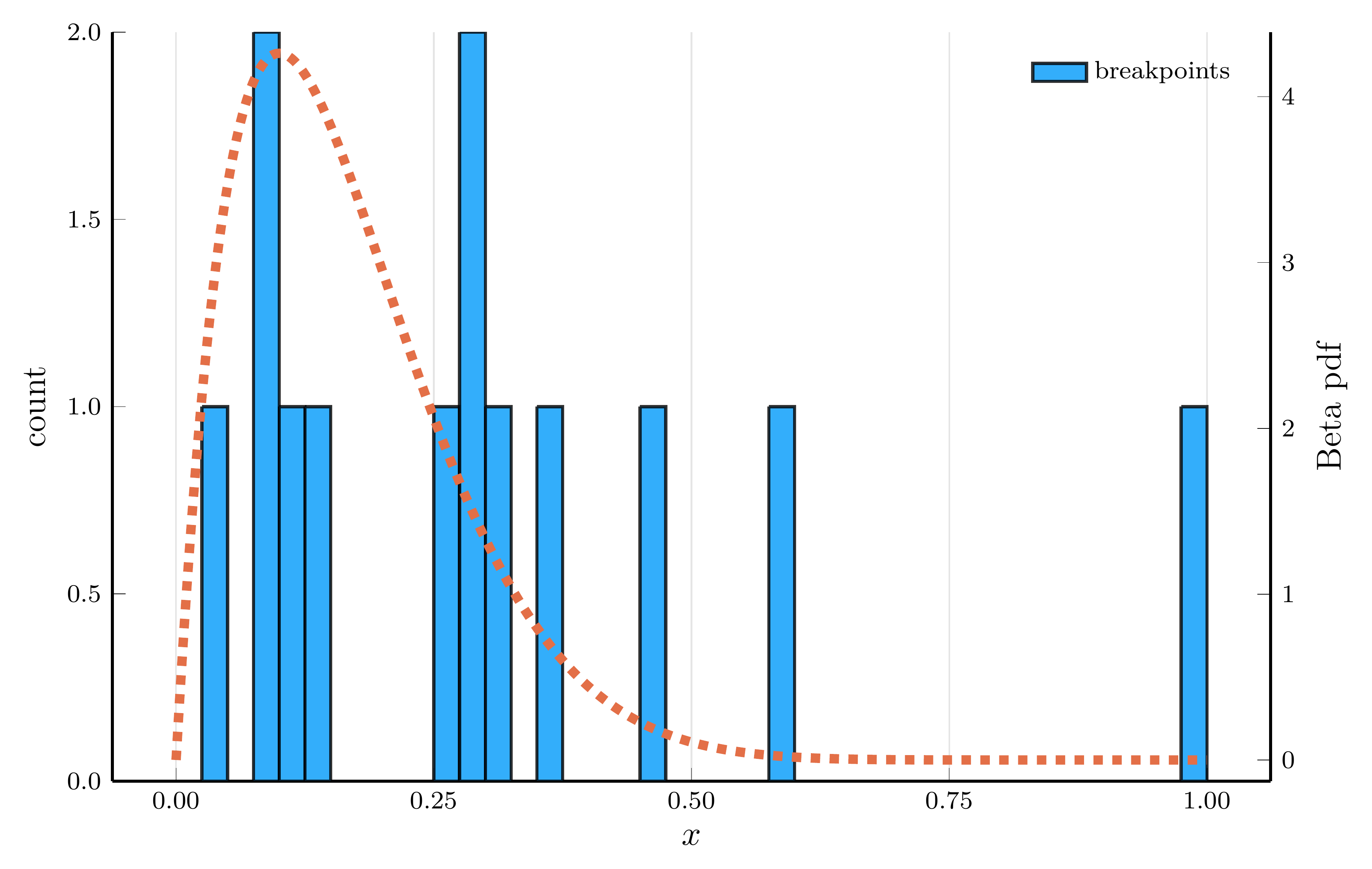
Breakpoint histogram (30 hidden units)
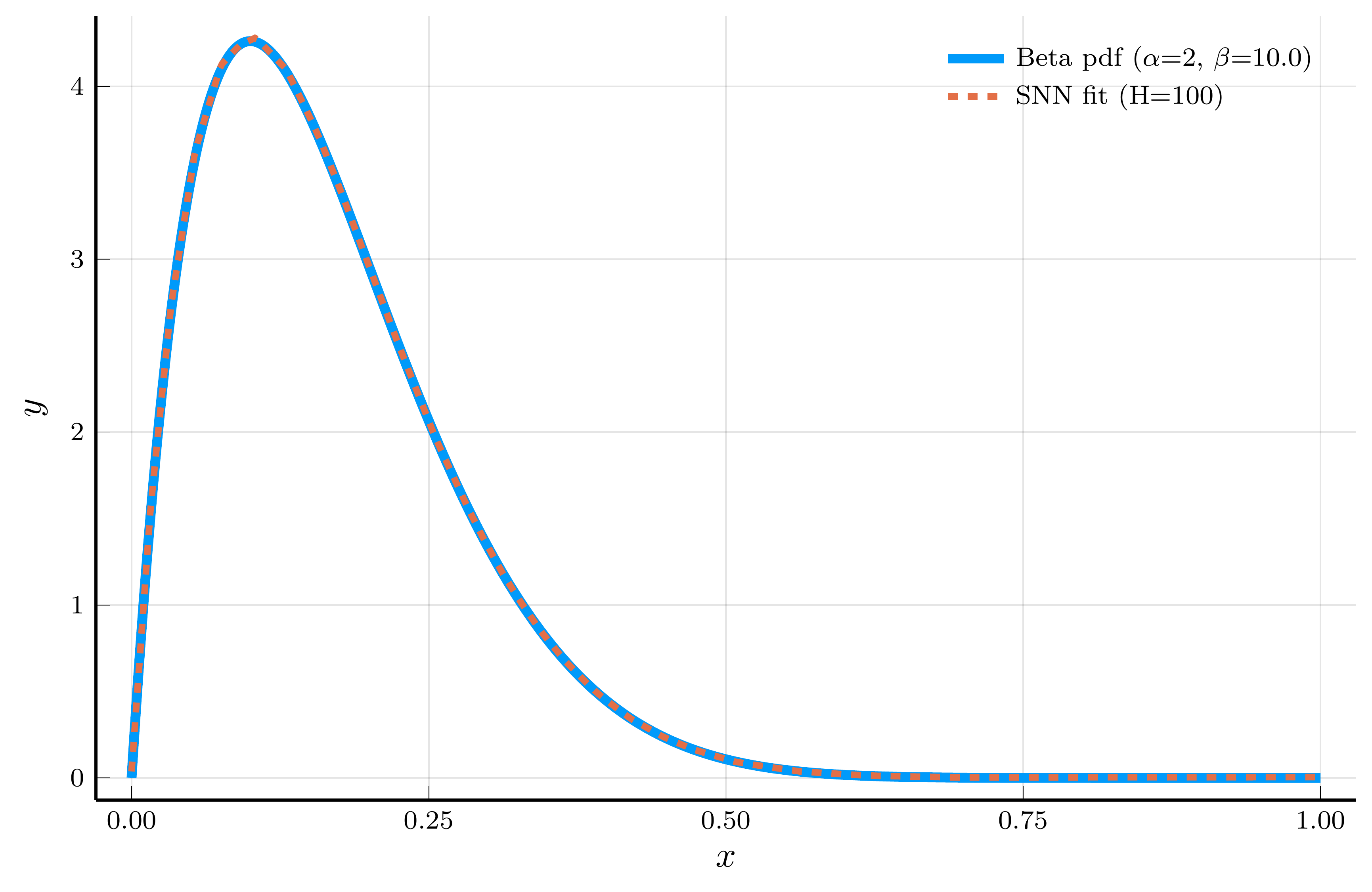
Model fit (100 hidden units)
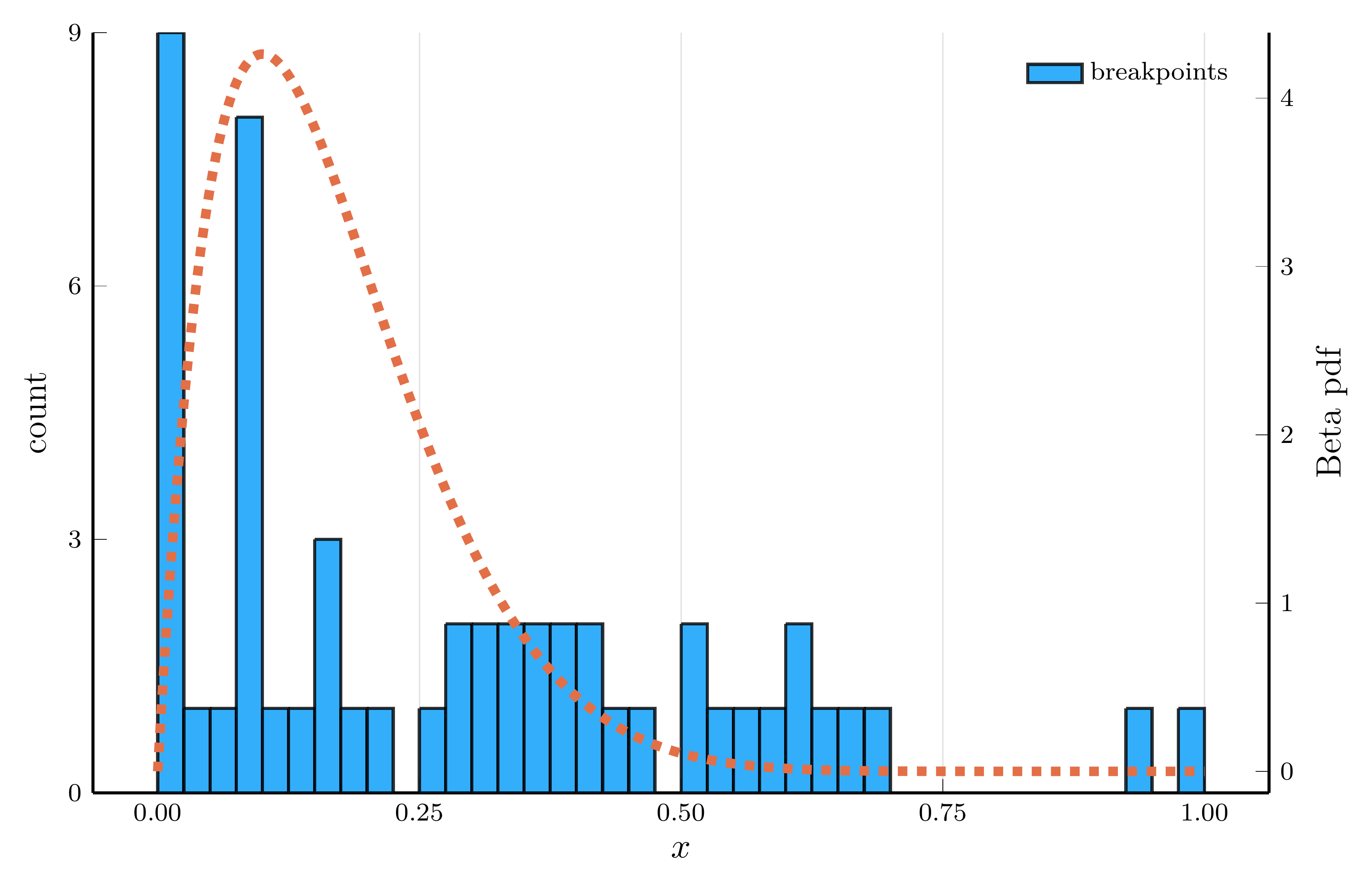
Breakpoint histogram (100 hidden units)
Deep Neural Networks
A shallow neural network contains a single hidden layer between the input and output layers.
- Deep neural networks (DNNs) extend this architecture by stacking multiple hidden layers on top of each other.
- Each layer applies a linear transformation followed by a nonlinear activation.
Formally, let the \(n_l\)-dimensional vector of hidden units at layer \(l\) be defined recursively as \[ \mathbf{h}_l(\mathbf{h}_{l-1}, \mathbf{\theta}_l) = \sigma(\mathbf{W}_l \mathbf{h}_{l-1} + \mathbf{b}_l), \qquad l = 1, \ldots, L-1, \] where \(\mathbf{\theta}_l = (\mathrm{vec}(\mathbf{W}_l)^{\top}, \mathbf{b}_l)^{\top}\) collects all parameters of layer \(l\).
The first hidden layer operates directly on the input: \[ \mathbf{h}_0(\mathbf{x}, \mathbf{\theta}_0) = \sigma(\mathbf{W}_0 \mathbf{x} + \mathbf{b}_0), \] and the output layer is given by \[ f(\mathbf{x}, \mathbf{\theta}) = \mathbf{W}_L \mathbf{h}_L + \mathbf{b}_L, \] where \(\mathbf{\theta} = (\mathbf{\theta}_0^{\top}, \ldots, \mathbf{\theta}_L^{\top})^{\top}\).
Example: Composition of Functions
To understand the expressive power of deep neural networks, consider composing a simple shallow ReLU network with itself. Let \[ f_1(x) = 2\sigma(x) - 4\sigma(x - 0.5), \] which produces a triangular function with a single kink at \(x = 0.5\).
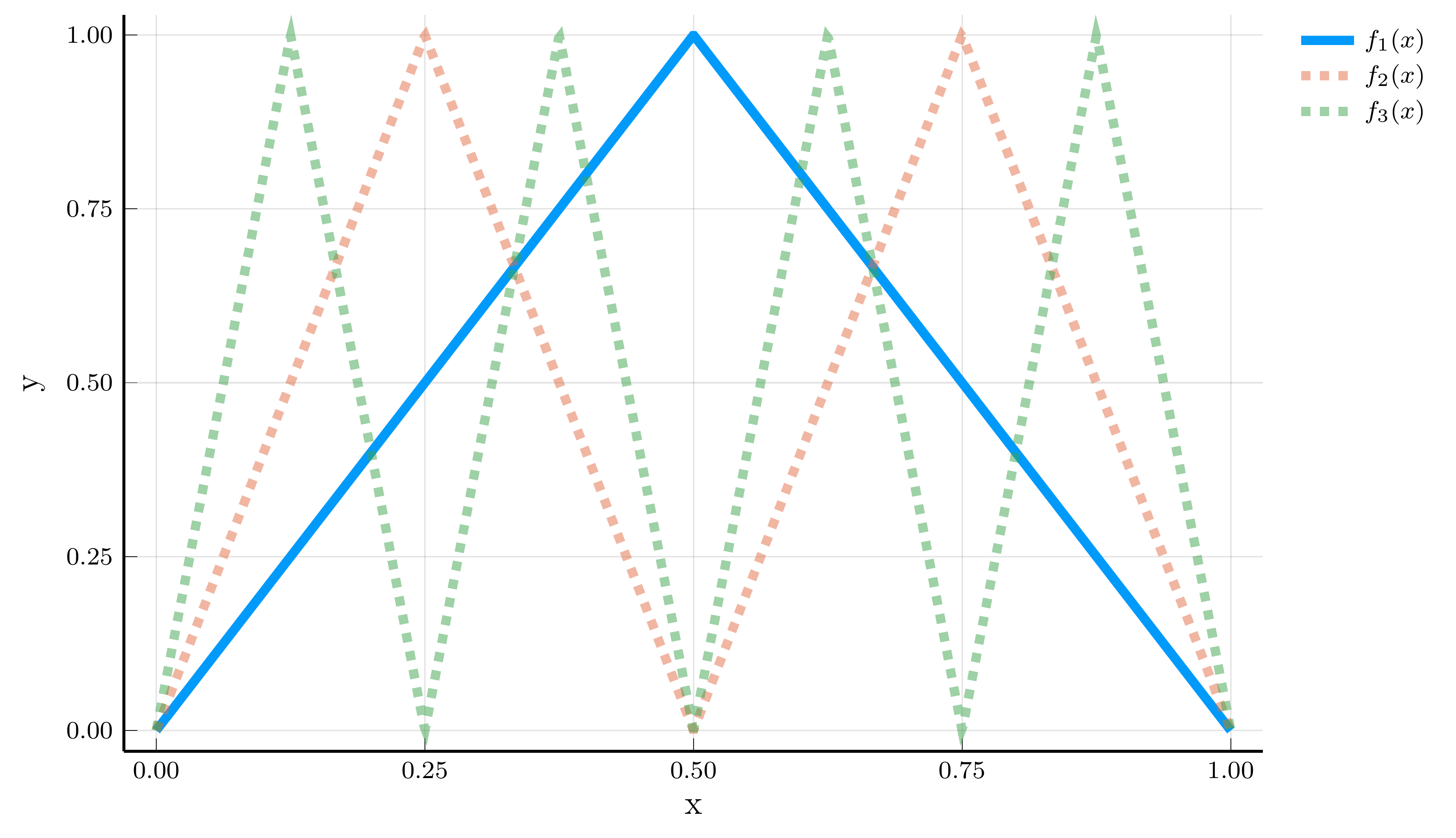
Realized functions \(f_k(x)\) for \(k = 1, 2, 3\)
Composing this function with itself yields \[ f_k(x) = 2\sigma(f_{k-1}(x)) - 4\sigma(f_{k-1}(x) - 0.5). \]
We can represent \(f_k(x)\) as a DNN with \(k\) hidden layers: \[ \mathbf{h}_l(x) = \begin{bmatrix} \sigma(f_{l-1}(x)) \\ \sigma(f_{l-1}(x) - 0.5) \end{bmatrix}. \]
The number of parameters required to represent \(f_k(x)\) is: \[ 4 + (k-1)\times 6 + 3 = 6k + 1. \]
The same function can also be represented as a shallow neural network
- It would require \(2^k\) hidden units to capture all linear regions.
- Depth provides an exponential gain in expressive efficiency.
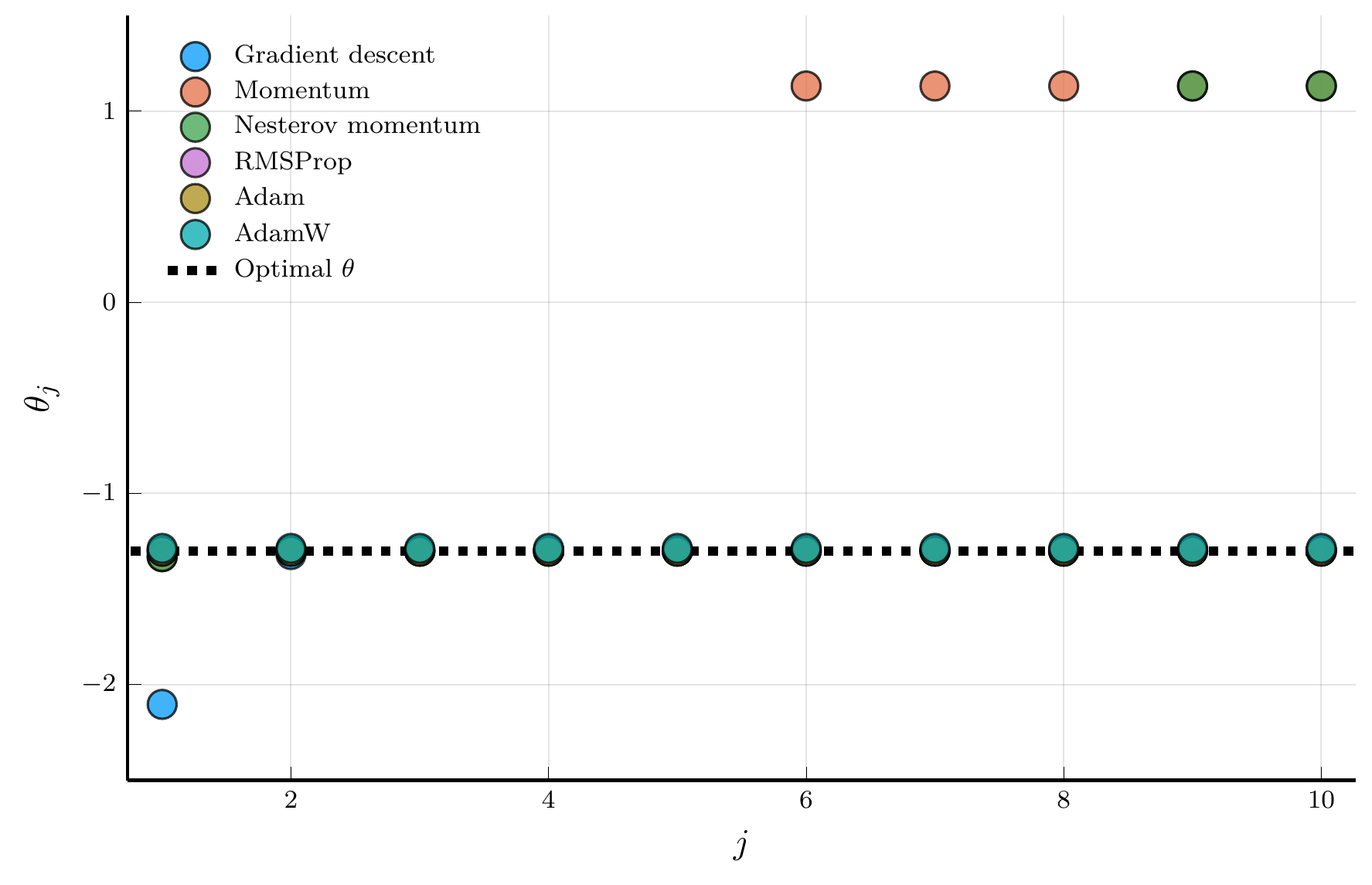
Updating the Parameters
To reproduce the function \(f_1(x)\), we can manually assign new values to the network parameters.
Luxallows direct updates through a named tuple with the same structure as the initialized parameters:
(layer_1 = (weight = [1.0; 1.0;;], bias = [0.0, -0.5]), layer_2 = (weight = [2.0 -4.0], bias = [0.0]))We can now evaluate the network on a grid of inputs:
1×9 Matrix{Float64}:
0.0 0.25 0.5 0.75 1.0 0.75 0.5 0.25 0.0
Defining a Deep Neural Network
To define a deeper network, we can stack multiple hidden layers.
Chain(
layer_1 = Dense(1 => 2, relu), # 4 parameters
layer_2 = Dense(2 => 2, relu), # 6 parameters
layer_3 = Dense(2 => 1), # 3 parameters
) # Total: 13 parameters,
# plus 0 states.
parameters, state = Lux.setup(rng, model)
parameters = (layer_1 = (weight = [1.0; 1.0;;], bias = [0.0, -0.5]),
layer_2 = (weight = [2.0 -4.0; 2.0 -4.0], bias = [0.0, -0.5]),
layer_3 = (weight = [2.0 -4.0], bias = [0.0]))
xgrid = collect(range(0.0, 1.0, length=9))
ygrid = model(xgrid', parameters, state)[1]'
plot(xgrid, ygrid, line = 3, xlabel = L"x", ylabel = L"f_2(x)", title = "Deep Neural Network", size = (400, 275), label = "")
Full-batch Gradient Descent vs. SGD
Let’s compare the full-batch GD and SGD in our simple example.
- The figure shows the trajectory of the full-batch GD (blue) and SGD (orange).
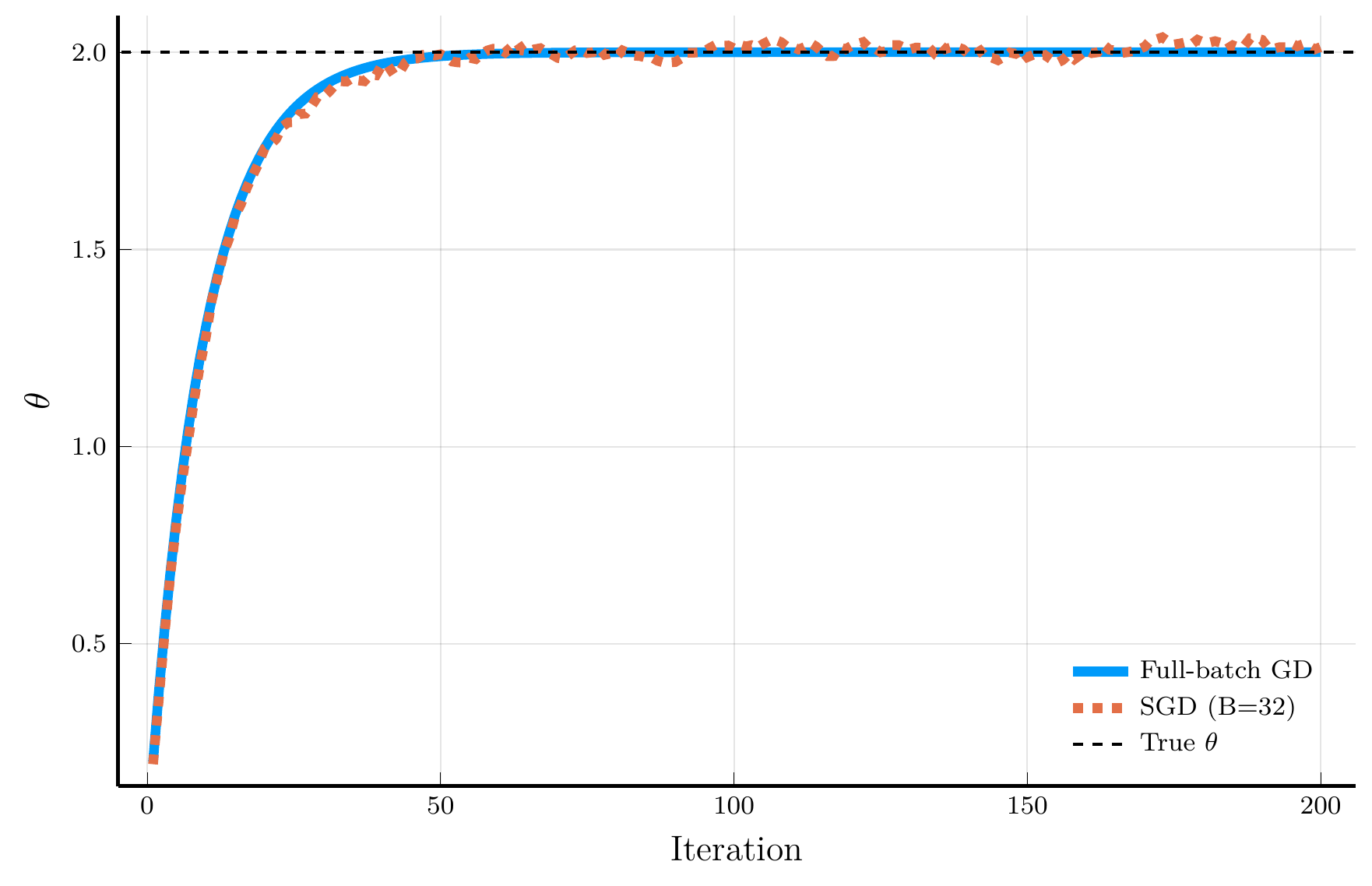
The full-batch GD converges monotonically to the true parameter.
- SGD introduces noise into the updates
- But converges to the true parameter at roughly the same rate.
SGD is much more efficient than full-batch GD.
- Full-batch GD requires \(I = 100,000\) evaluations of the gradient
- SGD only requires \(B = 32\) evaluations per iteration.
Non-convex Loss Landscape
The previous example considered a convex loss function, where both full-batch GD and SGD converge to the global minimum.
- An additional advantage of SGD emerges in non-convex problems
- Its inherent randomness can help escape local minima.
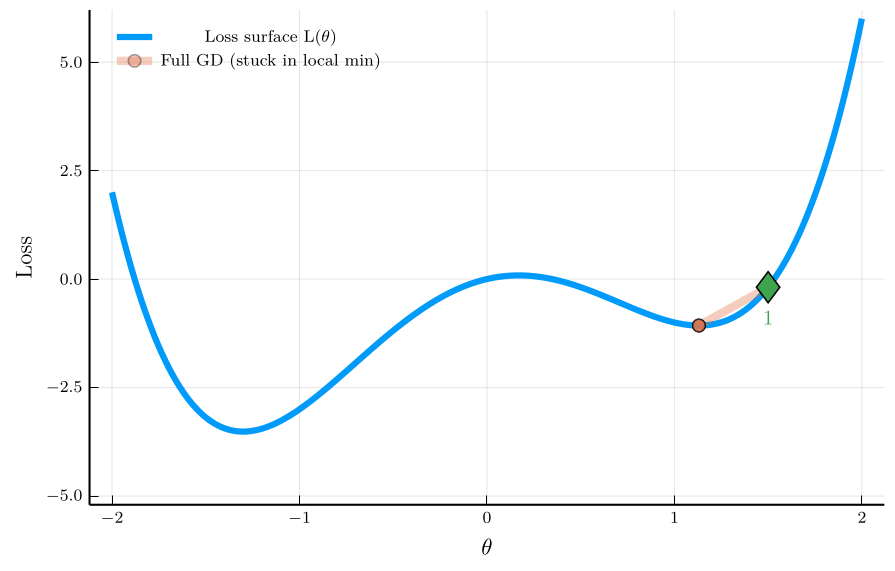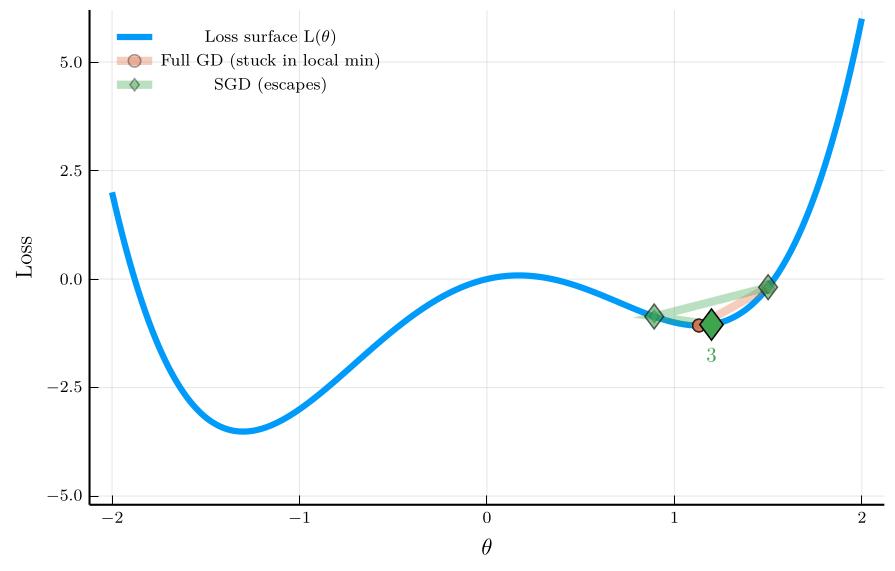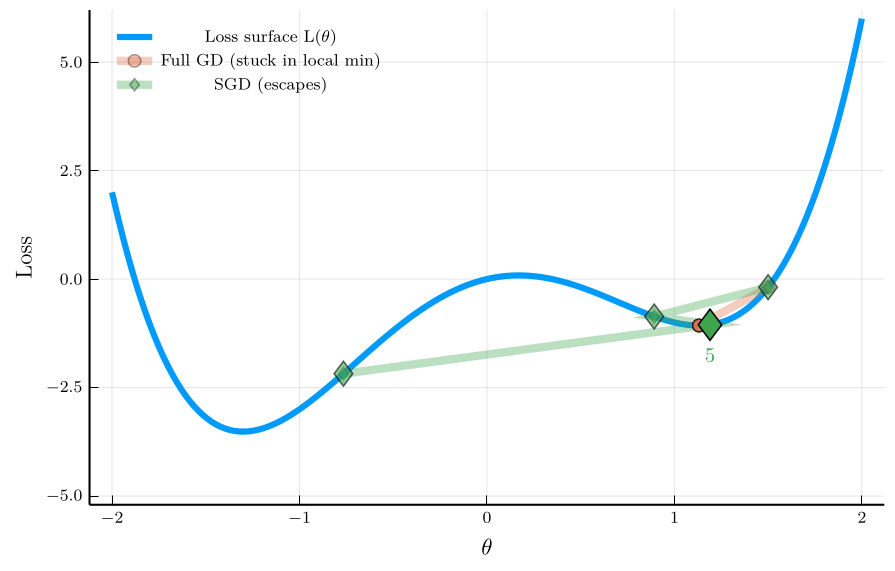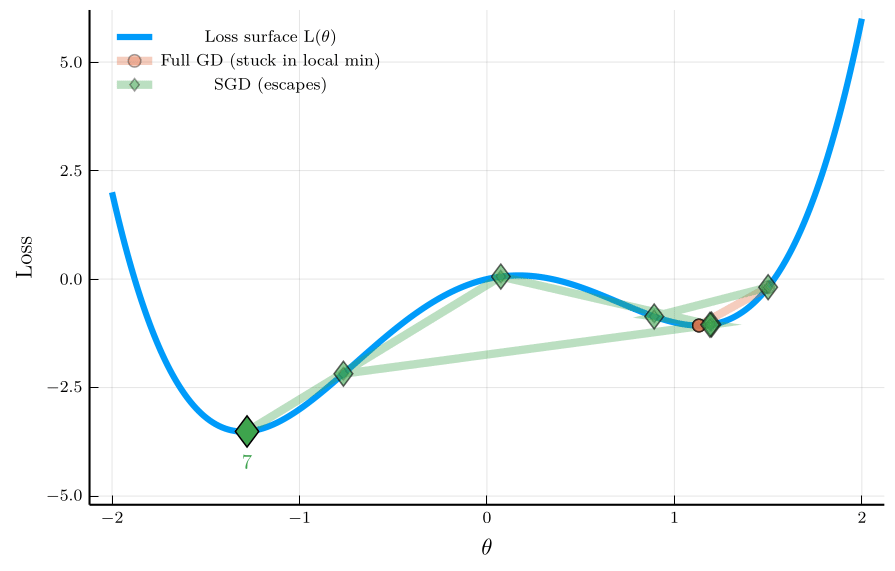
To illustrate the isse, consider the non-convex loss function:
\[ L(\theta) = \theta^4 - 3\theta^2 + \theta, \]
The figure shows the trajectory of full-batch GD and SGD.
- Full-batch GD gets stuck in a local minimum.
- SGD escapes the local minimum due to its noise.
This property is especially valuable in neural-network training,
- Loss landscapes are typically high-dimensional and non-convex.
Momentum vs. Gradient Descent
Consider the trajectory of gradient descent (blue) and momentum (orange).
- The loss surface has very different curvatures in different directions.
- Gradient descent oscillates and converges slowly.
- Momentum accelerates convergence by accumulating velocity in the direction of consistent gradients.
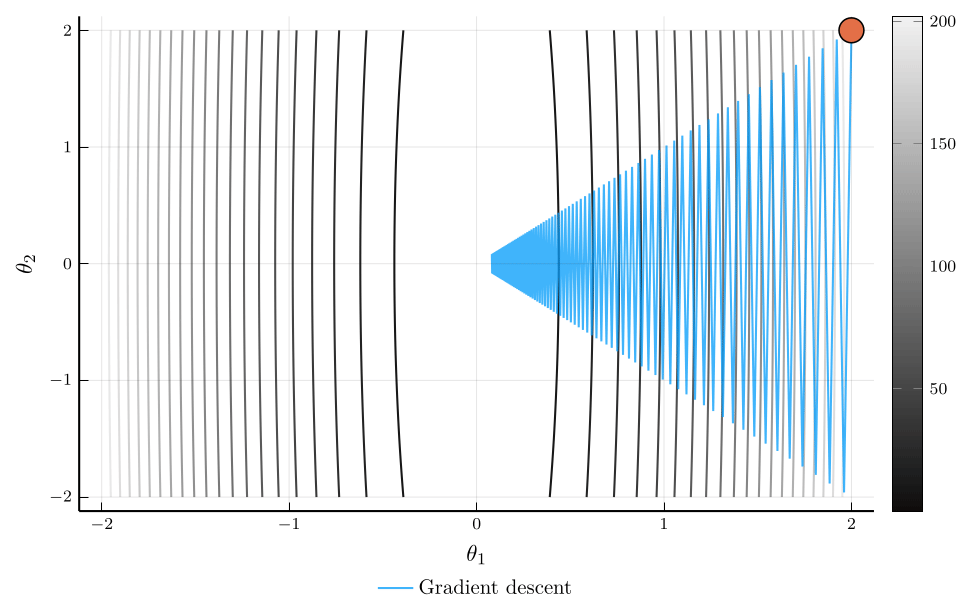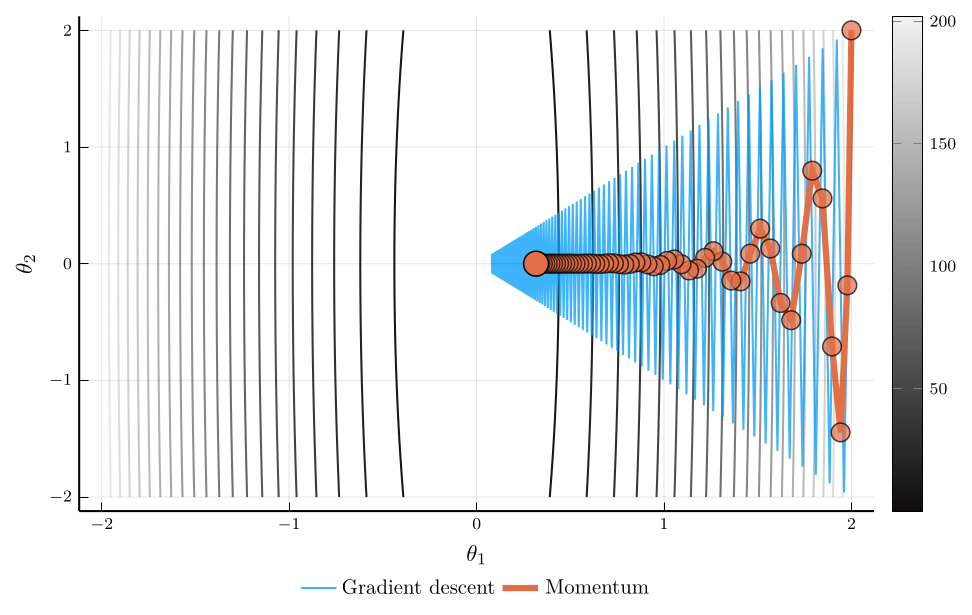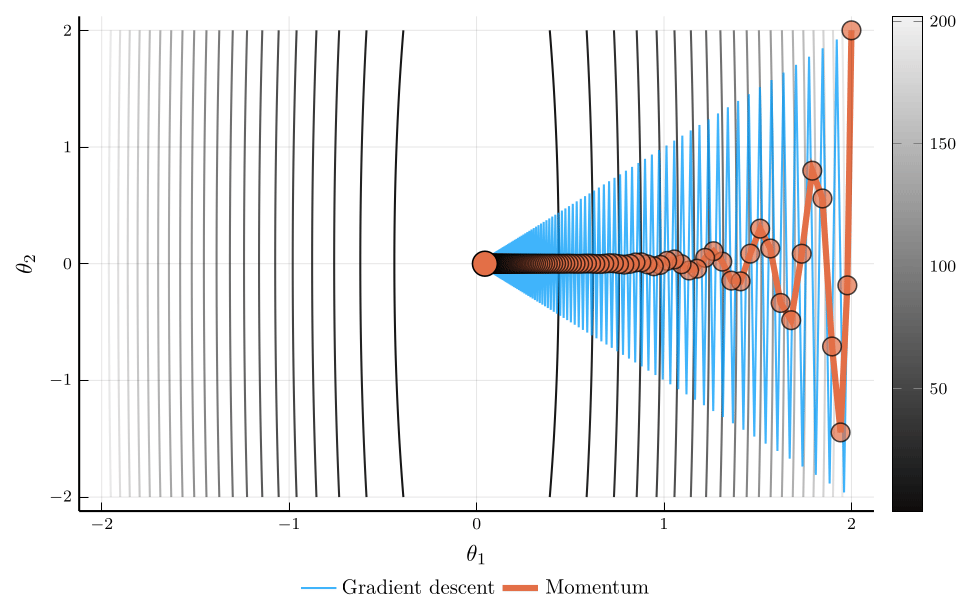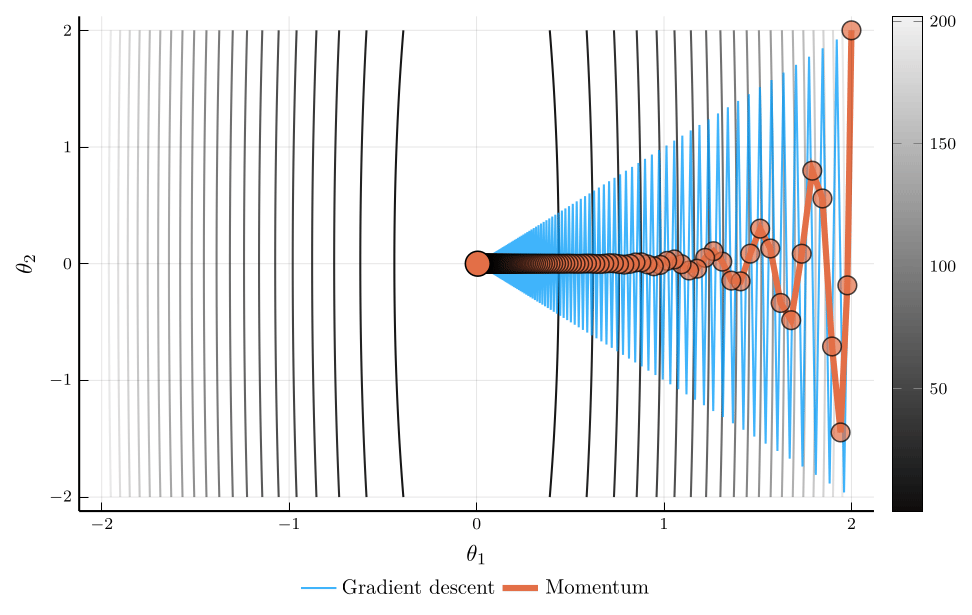
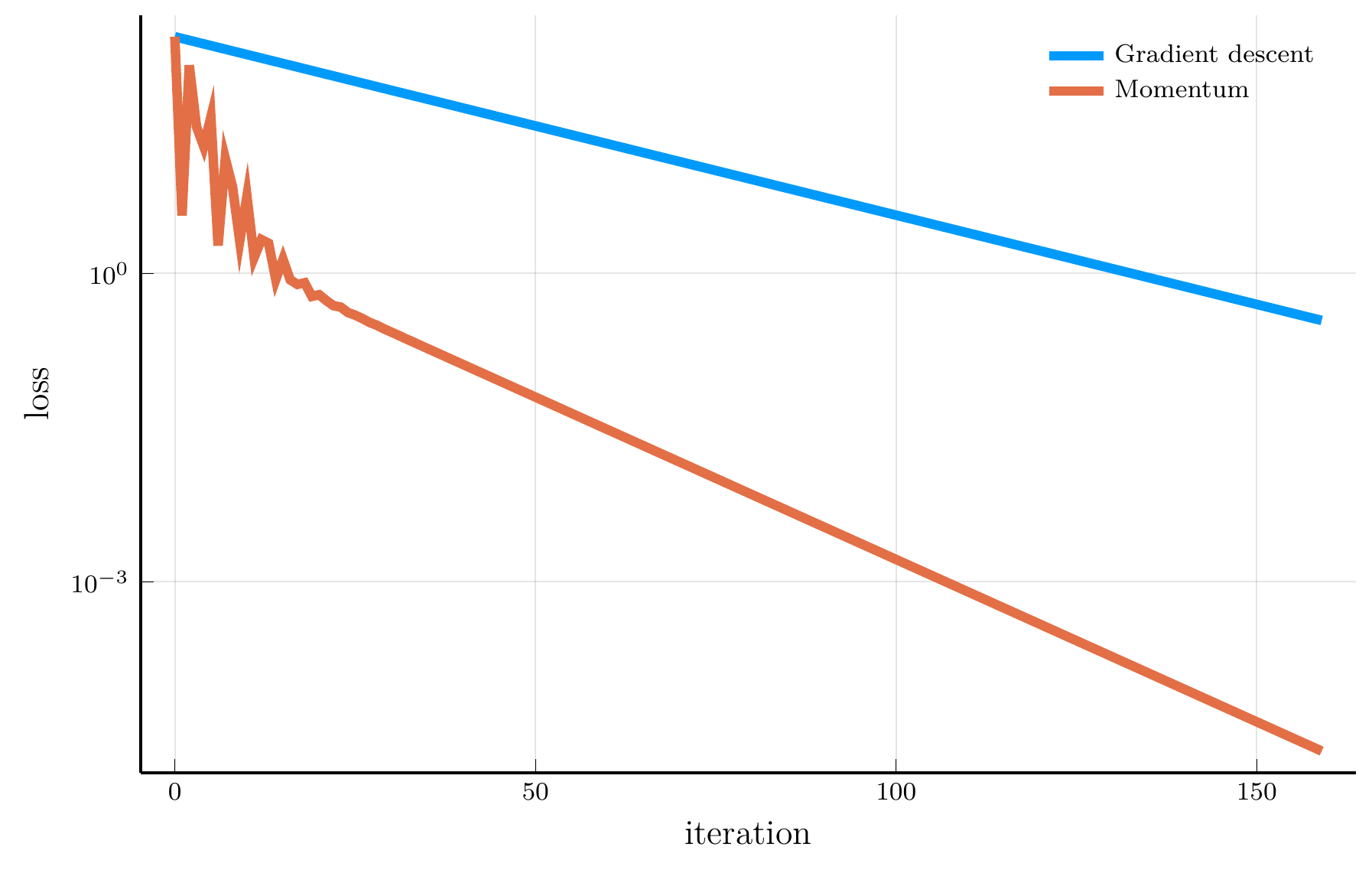
The loss plot confirms that momentum converges much faster than gradient descent.
RMSProp
When the curvature of the loss function varies across parameters, using a single learning rate \(\eta\) can be inefficient.
- RMSProp addresses this issue by scaling the learning rate according to the magnitude of recent gradients.
The root mean square propagation (RMSProp) algorithm defines: \[ \mathbf{v}_{n+1} = \rho \mathbf{v}_{n} + (1-\rho) (\nabla L(\mathbf{\theta}_n))^2, \] where \(\odot\) denotes elementwise multiplication.
The update rule for RMSProp is: \[ \mathbf{\theta}_{n+1} = \mathbf{\theta}_n - \eta \frac{\nabla L(\mathbf{\theta}_n)}{\sqrt{\mathbf{v}_{n+1}} + \epsilon}, \]
Intuitively, parameters with large gradients receive smaller updates.
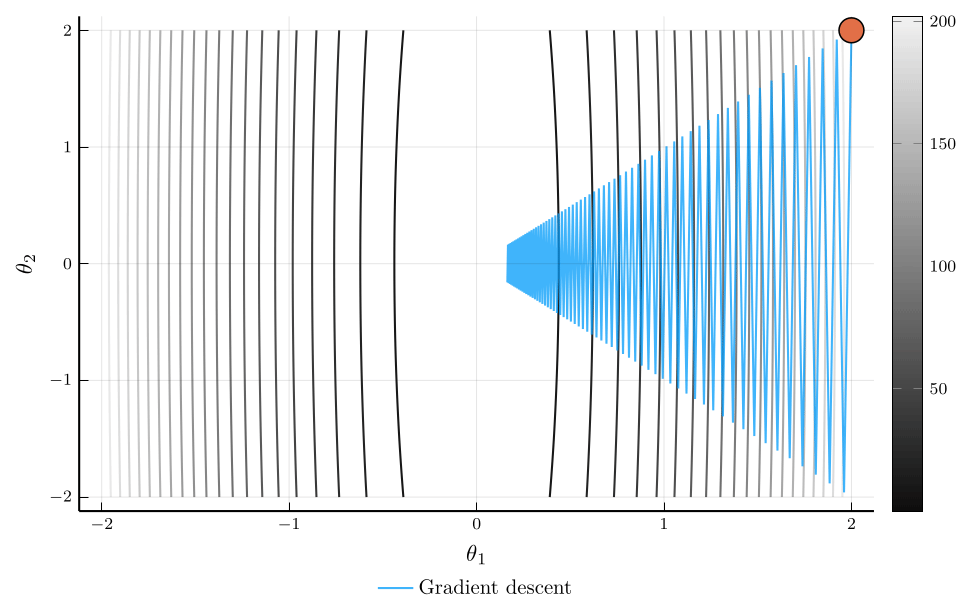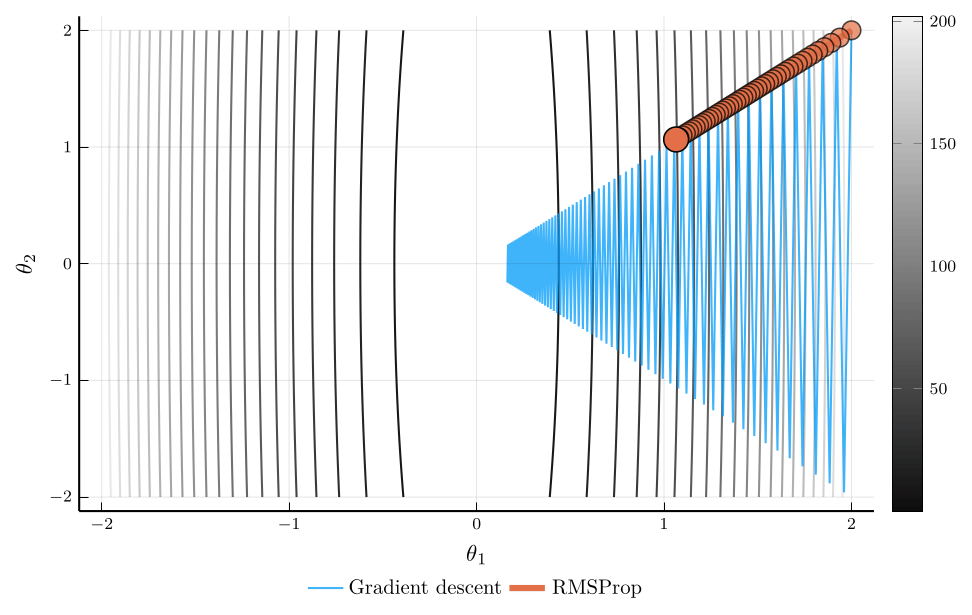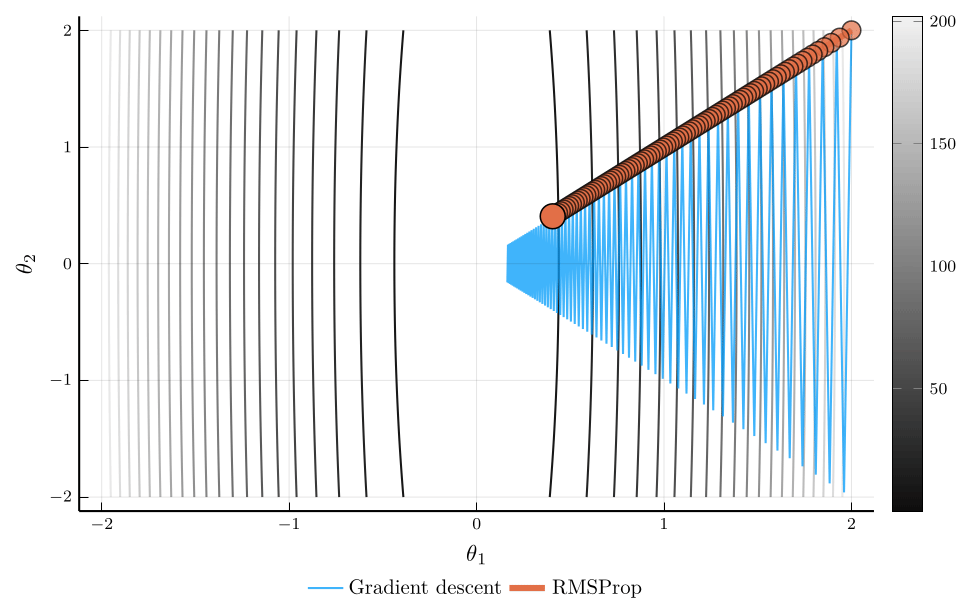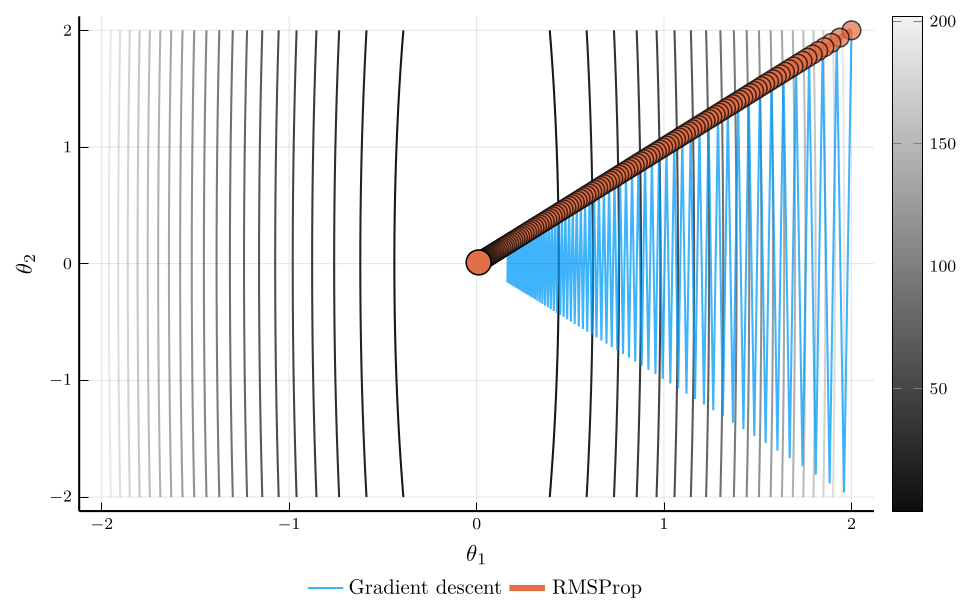
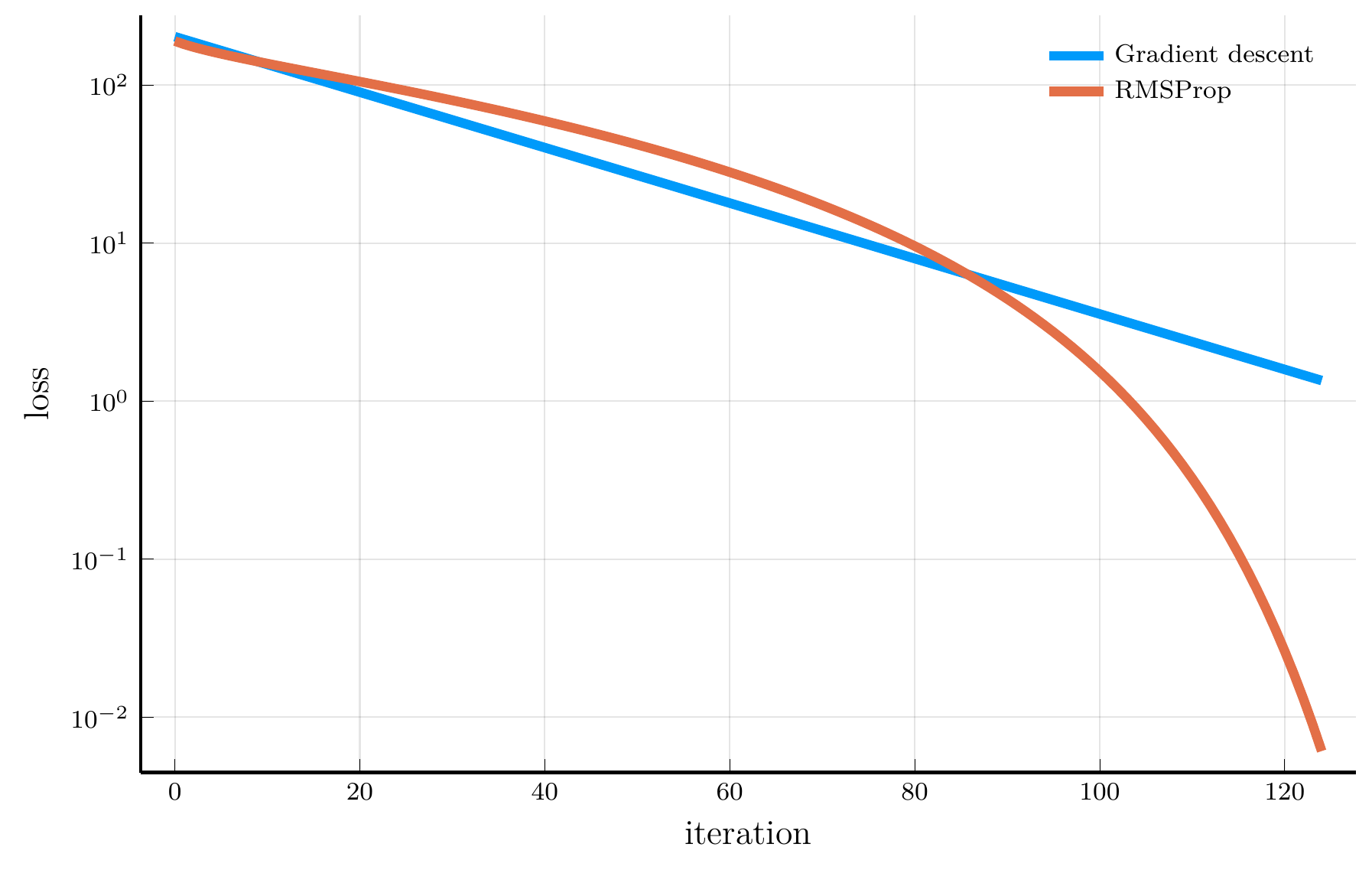
Comparing optimisers
Data and prediction for the DNN
The figure below presents the results.
- The left panel shows a random subsample of 256 data points (blue) and the corresponding DNN predictions (red)
- The two are nearly indistinguishable, indicating an excellent in-sample fit.
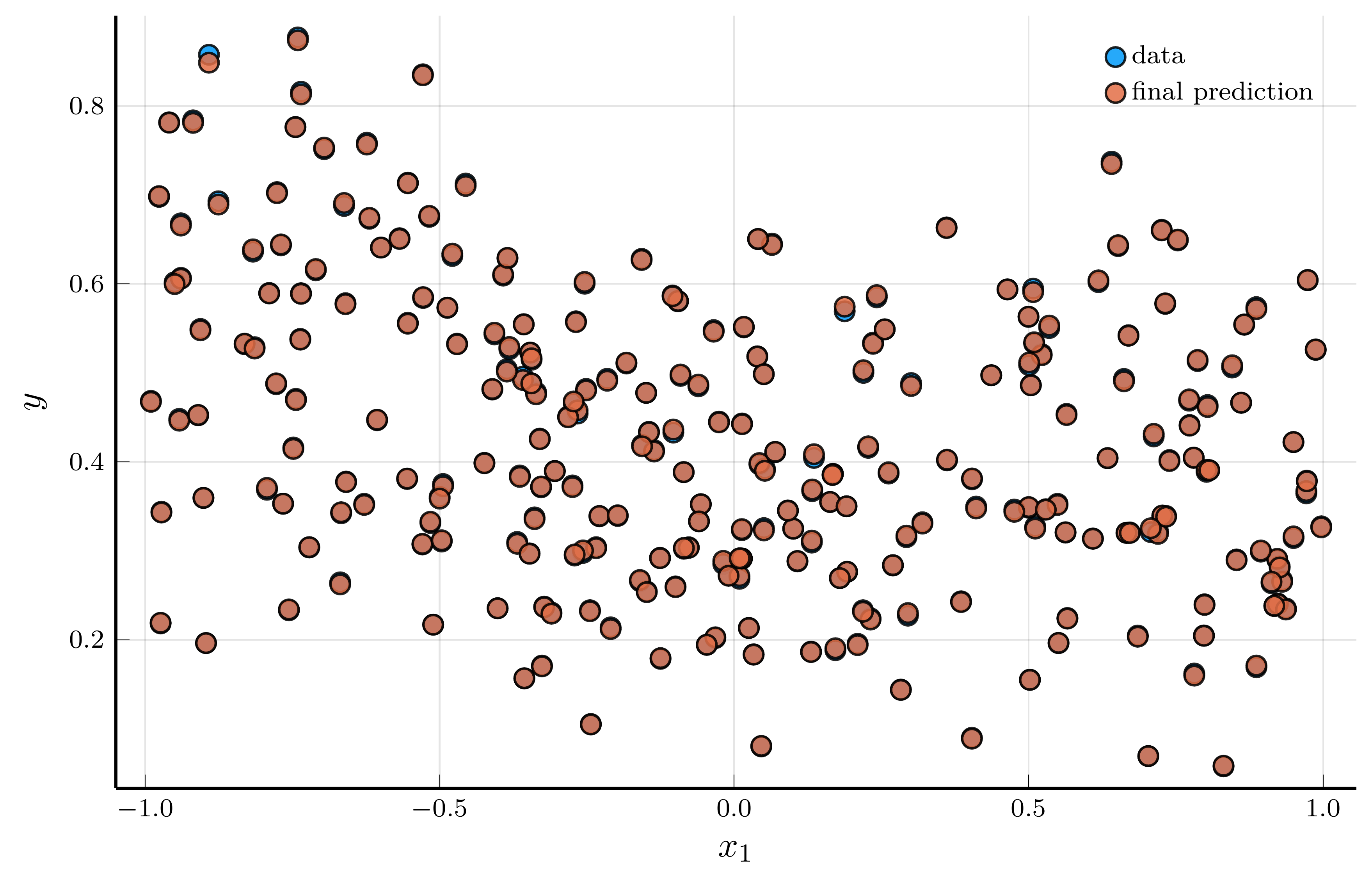
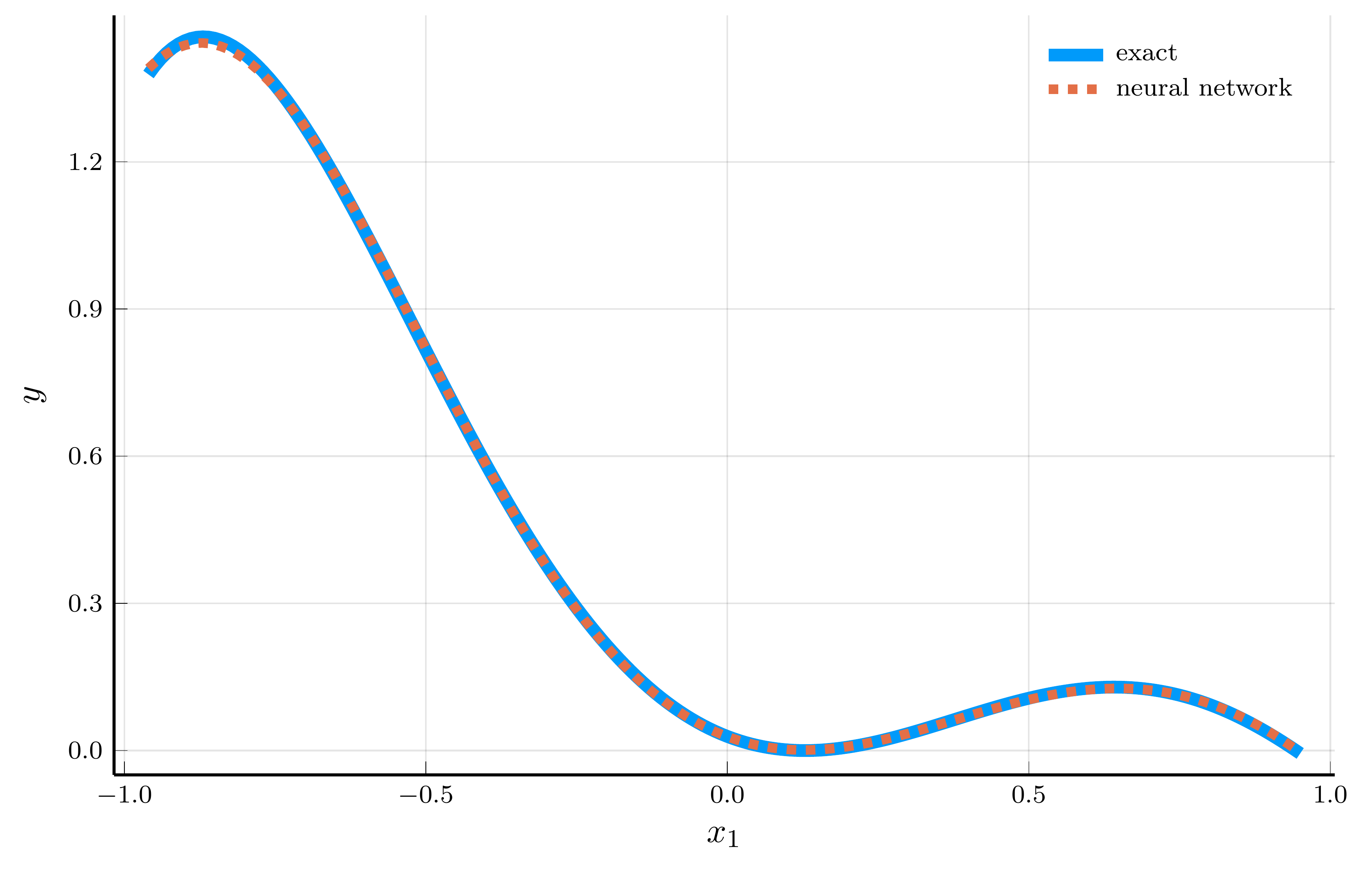
A natural concern is that the network might simply be memorizing the training data.
- To test this, we evaluate the network in the special case \(x_1 = x_2 = \cdots = x_n = x\)
- Then, \(f(\mathbf{x})\) reduces to \(p(x)\), a configuration that never appears in the random training sample.
Even without seeing this zero-probability case during training, the network’s predictions closely match \(f(\mathbf{x})\).
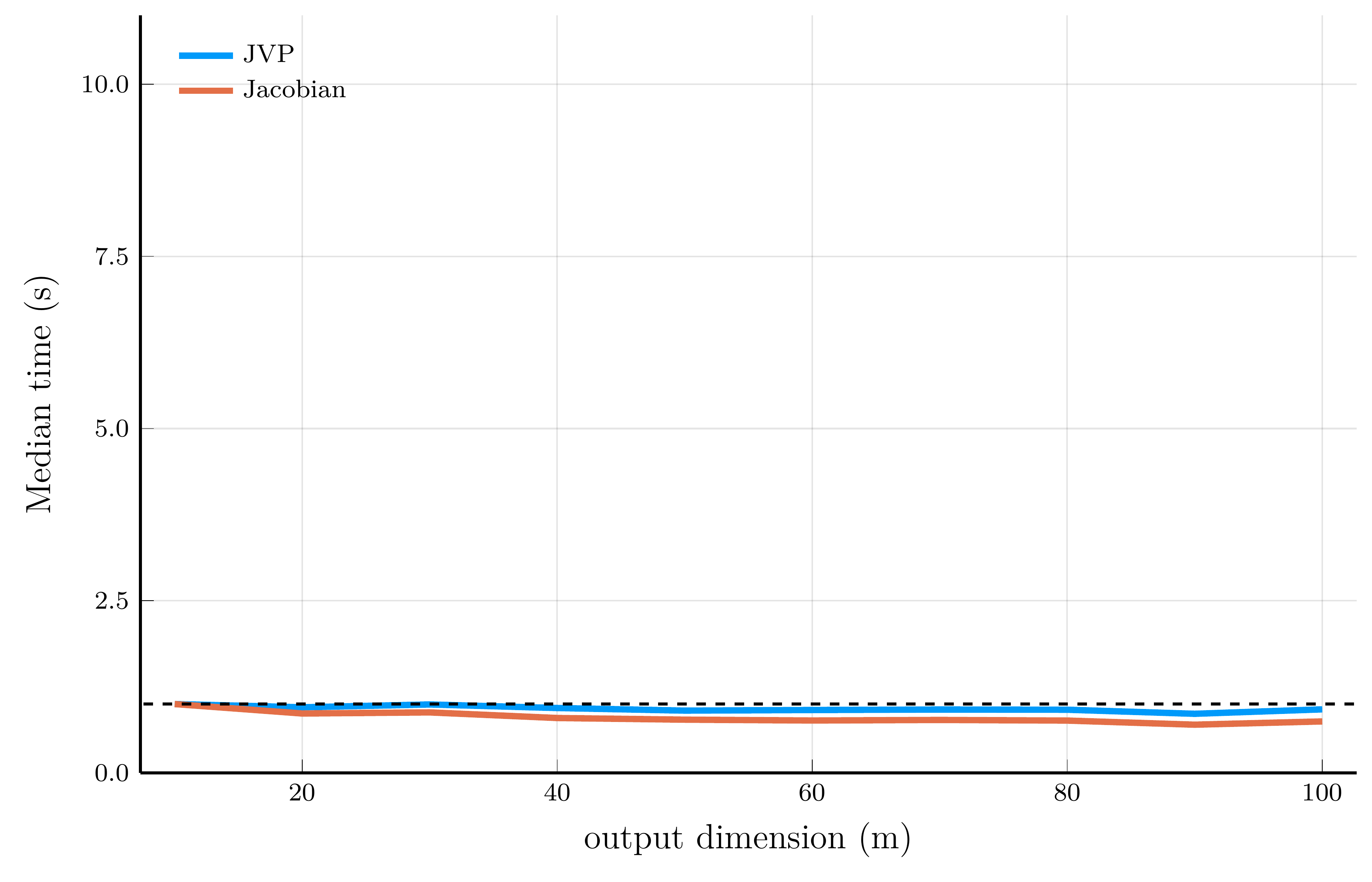
Computational efficiency of JVPs and full Jacobians
To illustrate the computational efficiency of JVPs and full Jacobians, we compare JVPs to full Jacobians on the test function \[ f_i(\mathbf{x}) = \exp\!\left(-\tfrac{1}{n}\sum_{j=1}^n \sqrt{x_j}\right) + i, \qquad \qquad \mathbf{f}(\mathbf{x}) = \big[f_1(\mathbf{x}), \ldots, f_m(\mathbf{x})\big]^\top \in \mathbb{R}^m. \]
We can implement the JVP and full Jacobian computations in Julia using the ForwardDiff.jl package.
# Test function
f(x; n = 1) = [exp(-mean(sqrt.(x)))+i for i = 1:n]
# Compute JVP
x, v = [1.0, 2.0, 3.0], [0.1, 0.2, 0.3]
xdual = ForwardDiff.Dual{Float64}.(x, v) # vector of dual numbers
ydual = f(xdual; n = 2) # evaluate function at dual numbers
jvp = ForwardDiff.partials.(ydual) # jvp
# Compute Jacobian
jac = ForwardDiff.jacobian(x->f(x; n = 2), x)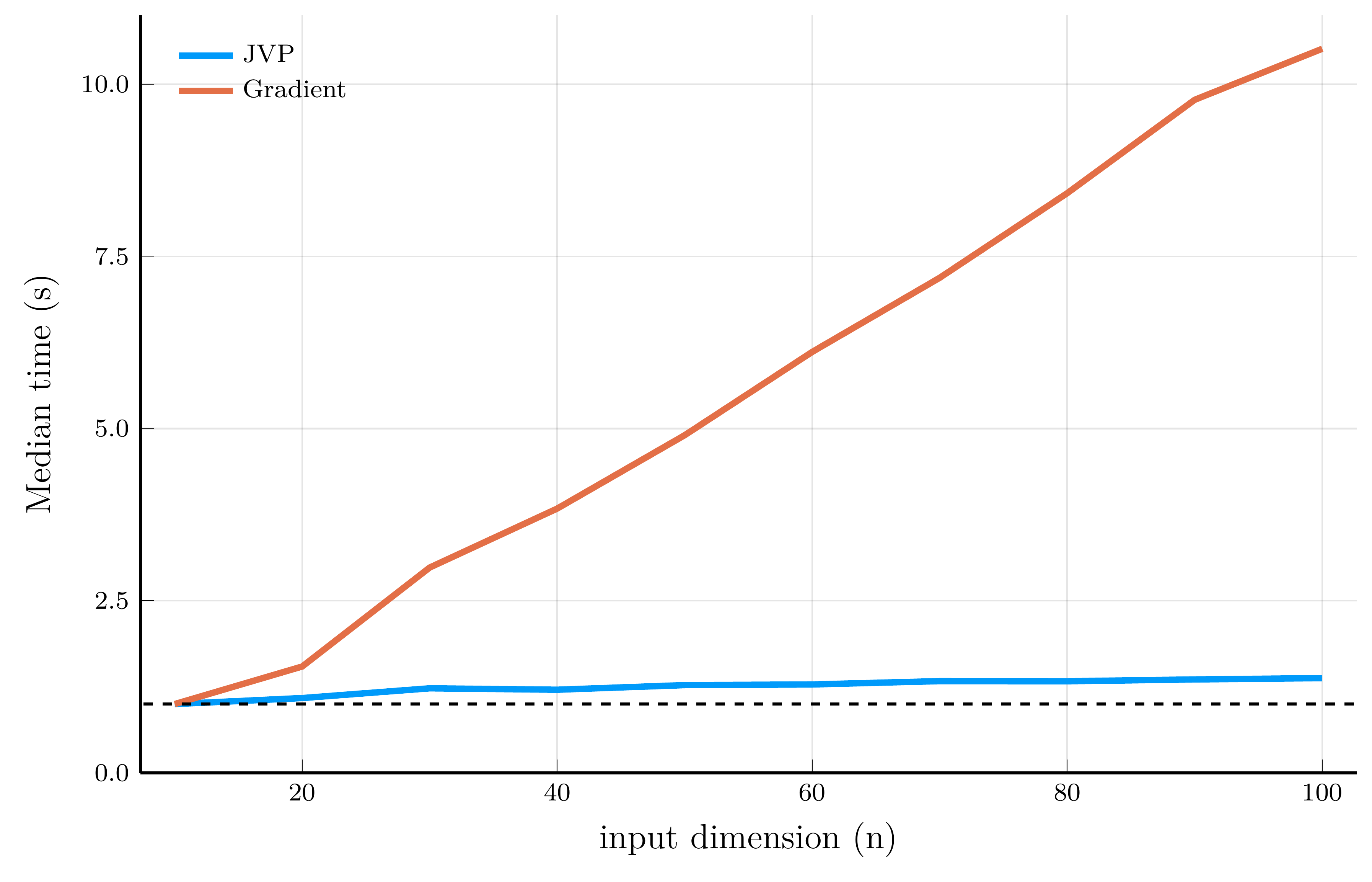
The computational graph
To understand how reverse mode works, it is useful to represent the function as a computational graph. Consider the function \[ f(x) = (x_1 + x_2)\,x_1^2. \]
Each operation in the function can be viewed as a node in a directed acyclic graph (DAG):
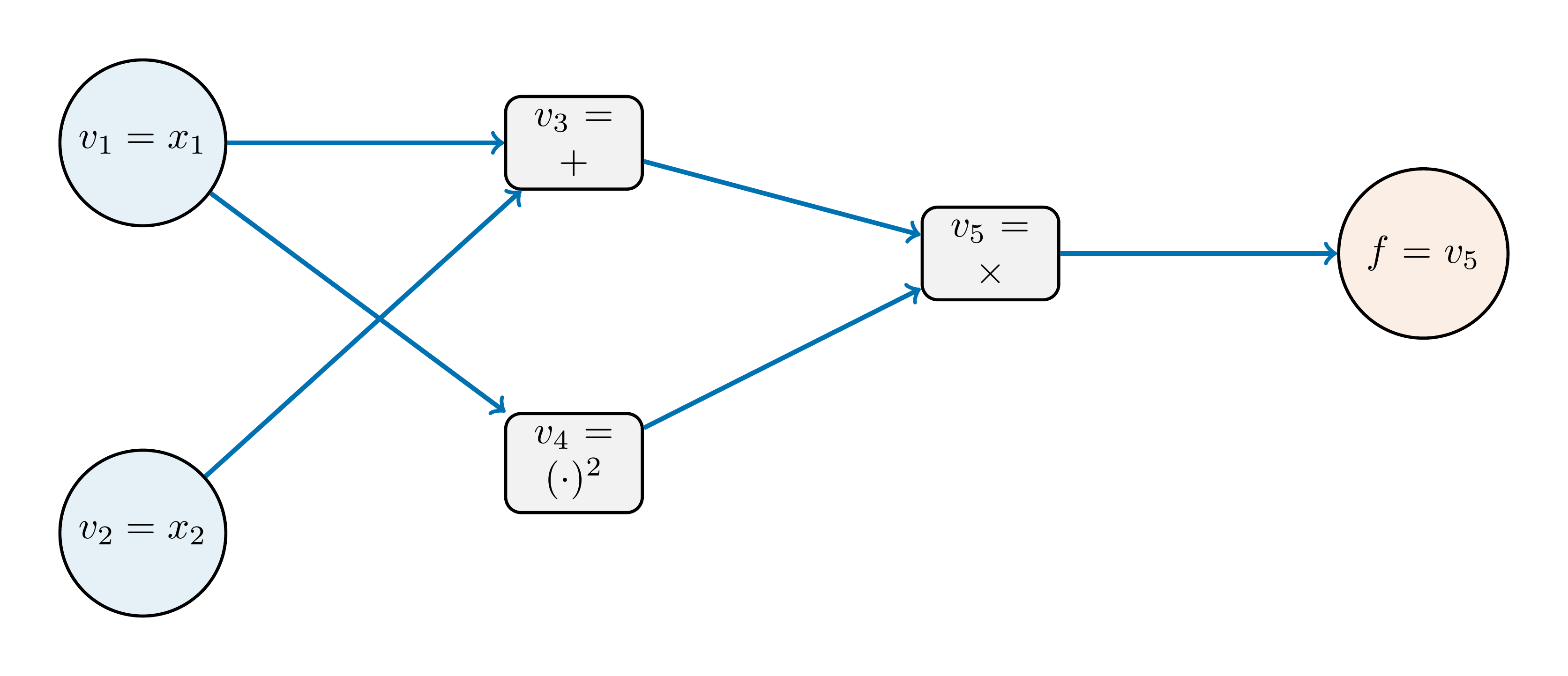
Reverse mode proceeds in two stages:
- A forward pass to compute and store the value at each node.
- A backward pass to accumulate gradients of the output with respect to each node.
Forward and backward passes
Forward pass: \[ v_1 = x_1, \qquad v_2 = x_2, \qquad v_3 = v_1 + v_2, \qquad v_4 = v_1^2, \qquad v_5 = v_3 v_4. \]
For \(x_1 = 1.0\) and \(x_2 = 2.0\), we obtain \[ v_1 = 1.0, \qquad v_2 = 2.0, \qquad v_3 = 3.0, \qquad v_4 = 1.0, \qquad v_5 = 3.0. \]
Backward pass:
- We seek \(\nabla_{\mathbf{x}} f = \left(\frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}\right)\). Define the adjoints as \(\overline{v}_i \equiv \frac{\partial f}{\partial v_i}\) for \(i = 1, 2, 3, 4, 5\).
- Starting from the output \(v_5\), we initialize its adjoint as \(\overline{v}_5 \equiv \frac{\partial f}{\partial v_5} = 1\)
The adjoints at the last nodes are \[ \overline{v}_3 = \overline{v}_5 \cdot v_4 = 1.0, \qquad \overline{v}_4 = \overline{v}_5 \cdot v_3 = 3.0. \]
Moving one step further back, the local derivatives are \[\begin{equation} \frac{\partial v_3}{\partial v_1} = 1, \quad \frac{\partial v_3}{\partial v_2} = 1, \quad \frac{\partial v_4}{\partial v_1} = 2v_1, \quad \frac{\partial v_4}{\partial v_2} = 0. \end{equation}\]
The adjoint for \(v_1\) collects contributions from two branches: \[ \begin{align} \overline{v}_1 &{+}= \overline{v}_3 \frac{\partial v_3}{\partial v_1} = 1 \cdot 1 = 1,\\ \overline{v}_1 &{+}= \overline{v}_4 \frac{\partial v_4}{\partial v_1} = 3 \cdot 2v_1 = 6. \end{align} \]
Variable \(v_2\) affects only \(v_3\), so \[ \overline{v}_2 = \overline{v}_3 \frac{\partial v_3}{\partial v_2} = 1 \cdot 1 = 1. \] \[ \frac{\partial f}{\partial x_1} = \overline{v}_1 = 7, \qquad \frac{\partial f}{\partial x_2} = \overline{v}_2 = 1. \]
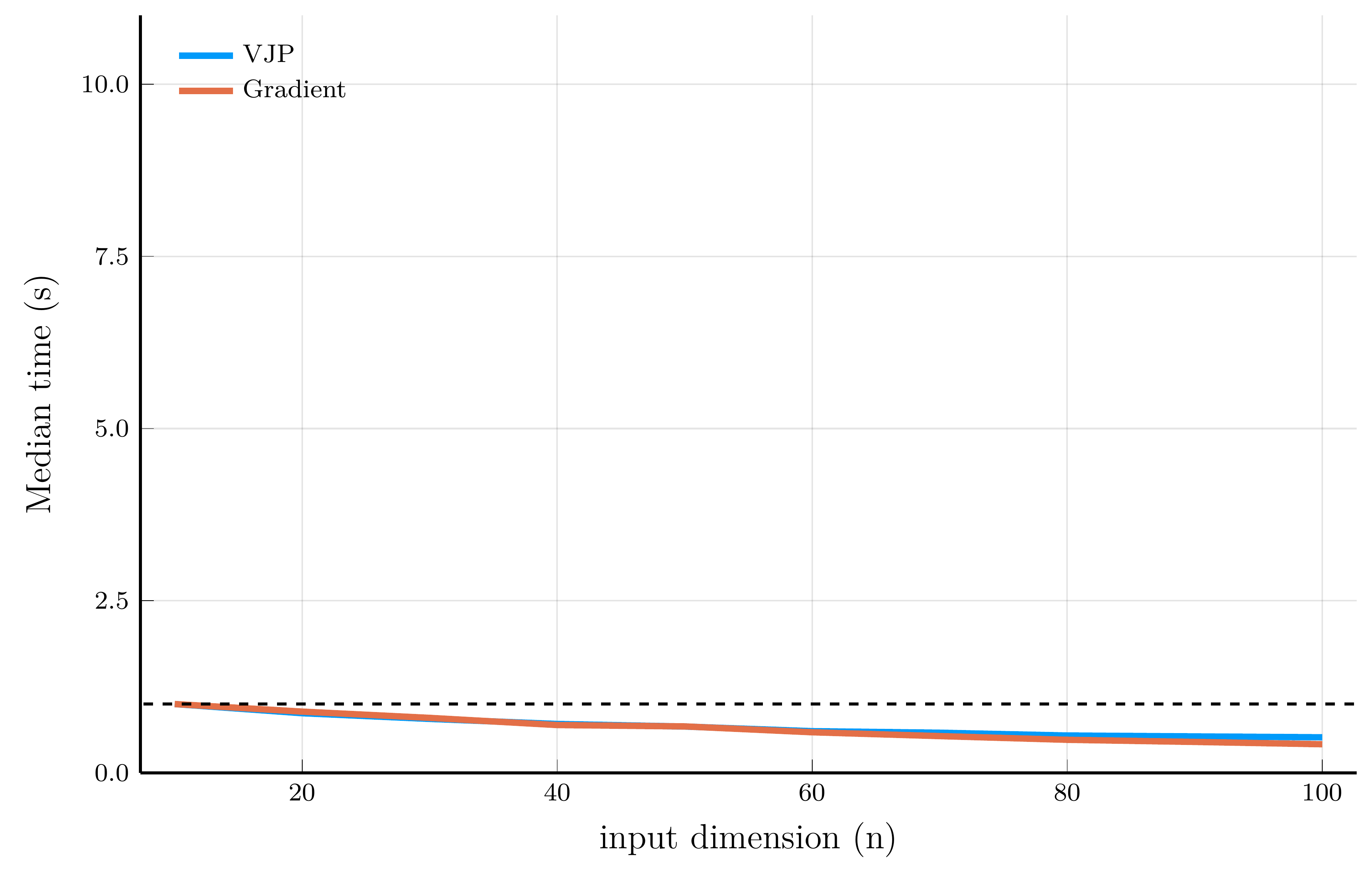
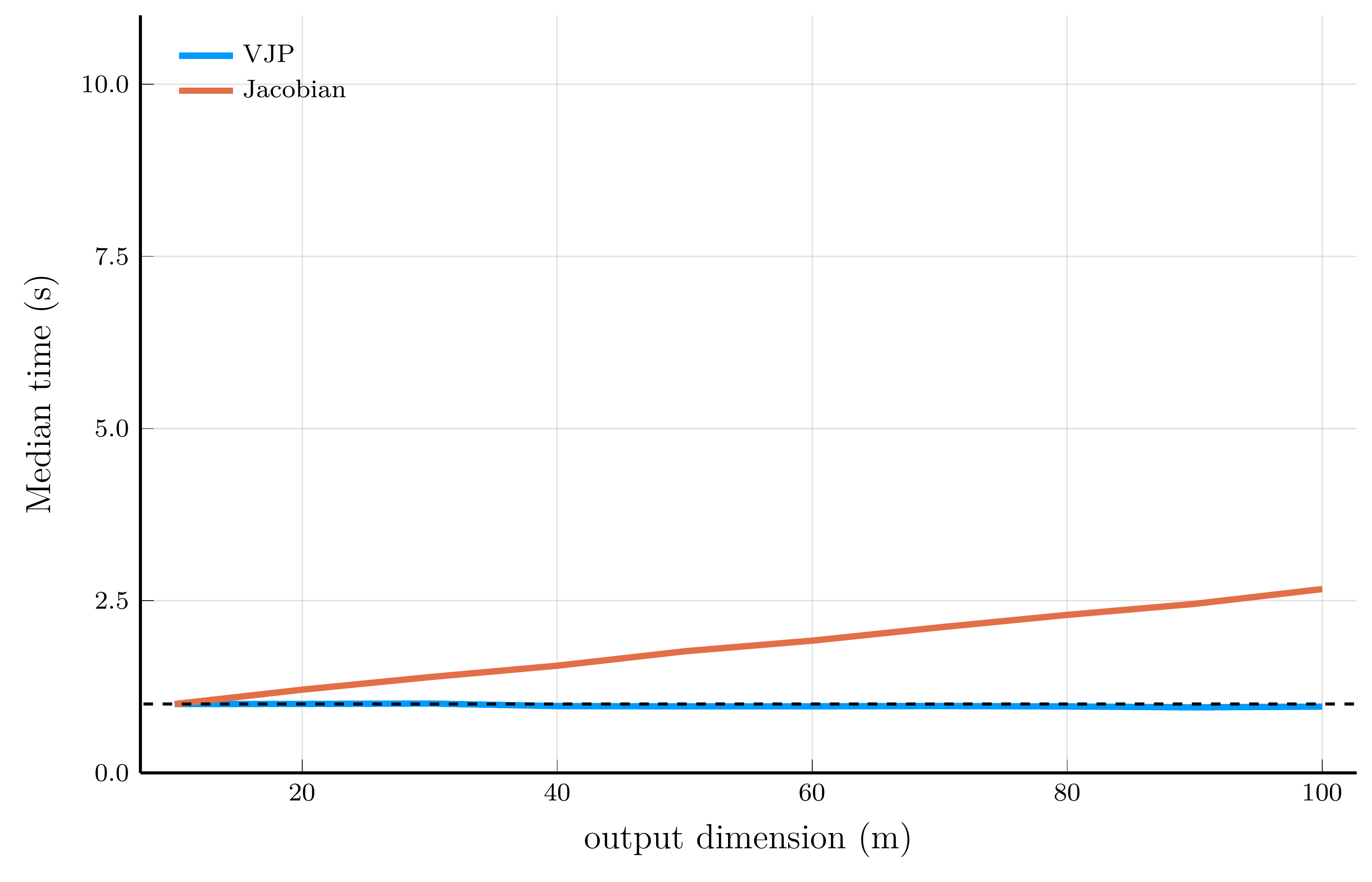
Performance comparison
We now illustrate the scaling properties of reverse-mode AD using Zygote.jl.
- We employ the same test functions used in the forward-mode AD performance comparison.
For scalar-valued functions (left panel), the cost of a VJP is independent of the input dimension \(n\)
- For vector-valued functions (right panel), computing the full Jacobian requires one backward pass per output dimension.
Taking stock.
Automatic differentiation provides an efficient way to compute gradients of functions.
- Forward-mode excels when the output dimension is large, while reverse-mode is better when the input dimension is large.